Learn how adaptive concurrency in the OpenFaaS queue-worker prevents overloading functions, reduces retries, and completes async batches faster — without per-function tuning.
Synchronous vs. asynchronous invocation
Any OpenFaaS function can be called synchronously (the default) or asynchronously via a queue. The difference is similar to calling a function and waiting for its return value, versus deferring work — like defer in Go, async/await in Node/Python, or submitting a job to a batch-processing queue.
Synchronous — caller waits for the result

The caller sends an HTTP request and waits. The gateway proxies it to the function and streams the response back. Simple and direct, but the caller is blocked for the full duration — if the function takes 5 minutes, the caller waits 5 minutes.
Asynchronous — caller returns immediately, work is processed in the background

The caller sends a request to /async-function/<name> and gets back a 202 Accepted with a X-Call-Id within milliseconds. The gateway serialises the request onto a NATS JetStream queue. The queue-worker subscribes, pulls messages off the queue, and invokes the function. If a X-Callback-Url header was provided, the result is POSTed there when done.
This is a hybrid of a batch-job queue and deferred execution — think of it as submitting a job and optionally subscribing to the result. It is ideal for long-running work, batch processing, webhooks with tight response-time contracts, and fan-out pipelines.
Where queue-worker dispatch falls short
By default the queue-worker uses greedy dispatch — pulling messages and sending them to the function as fast as possible. This works well and is used widely in production, but for functions with strict concurrency limits it can cause excessive retries, and requires careful per-function tuning for optimal performance.
Adaptive concurrency is a new dispatch mode that fixes this. The queue-worker learns each function’s capacity and throttles dispatch to match automatically. It addresses two problems in particular:
- Known concurrency limit — the function has
max_inflightset, capping concurrent requests per replica. The total capacity changes as replicas scale up and down. - Variable upstream capacity — the function depends on an external resource — a database, a third-party API — that can slow down or become overloaded. The function signals back-pressure by returning
429itself.
How adaptive concurrency solves this
Adaptive concurrency removes the tuning burden. Instead of dispatching as fast as possible and dealing with rejections, the queue-worker learns how much work each function can handle and throttles the dispatch rate to match automatically.
The result:
- Fewer retries — requests are held in the queue until the function can accept them
- Faster batch completion — no time wasted in exponential back-off
- No per-function tuning — the algorithm adapts to each function’s behaviour on its own
- Handles dynamic capacity — automatically adjusts as replicas scale up and down or upstream capacity changes

Why does the default approach generate retries?
Without adaptive concurrency, the queue-worker uses what we call a greedy dispatch algorithm. It pulls messages from the NATS JetStream queue and sends them to the function as fast as possible. When a function has max_inflight set — say to 5 per replica — the first 5 requests succeed, and the rest are rejected with 429 status codes.
The queue-worker then retries the rejected requests with exponential back-off. As the autoscaler adds more replicas, capacity increases, more requests succeed, and the backlog eventually clears. But during this ramp-up period, a large proportion of the requests are retried one or more times.
How adaptive concurrency works
Adaptive concurrency flips the approach. Instead of dispatching as fast as possible and dealing with rejections, it learns the function’s capacity and throttles dispatch to match.
The algorithm is feedback-driven:
- Start low — the queue-worker begins with a concurrency limit of zero for each function and grows it incrementally based on real responses.
- Increase on success — after receiving a successful response, the limit is increased. After a sustained period without rejections, it scales up more aggressively.
- Back off on rejection — after consecutive
429responses, the limit is reduced with a safety margin below the discovered maximum to avoid repeatedly hitting the ceiling. - Proactive scaling — the queue-worker periodically checks whether there’s a backlog of queued work. If there is, it proactively increases the concurrency limit to fill available capacity.
- Adapt to replica changes — as the autoscaler adds or removes replicas, the function’s ability to accept requests changes. The algorithm detects this through the success/failure feedback loop and adjusts accordingly.
The net effect is that the queue-worker holds messages in the queue until the function can accept them, rather than sending them only to have them rejected and retried.
Greedy vs. adaptive concurrency — a side-by-side comparison
To show the difference, we ran the same workload with both approaches. We deployed the sleep function from the OpenFaaS store with a max_inflight of 5 and a maximum of 10 replicas, then submitted a batch of asynchronous invocations.
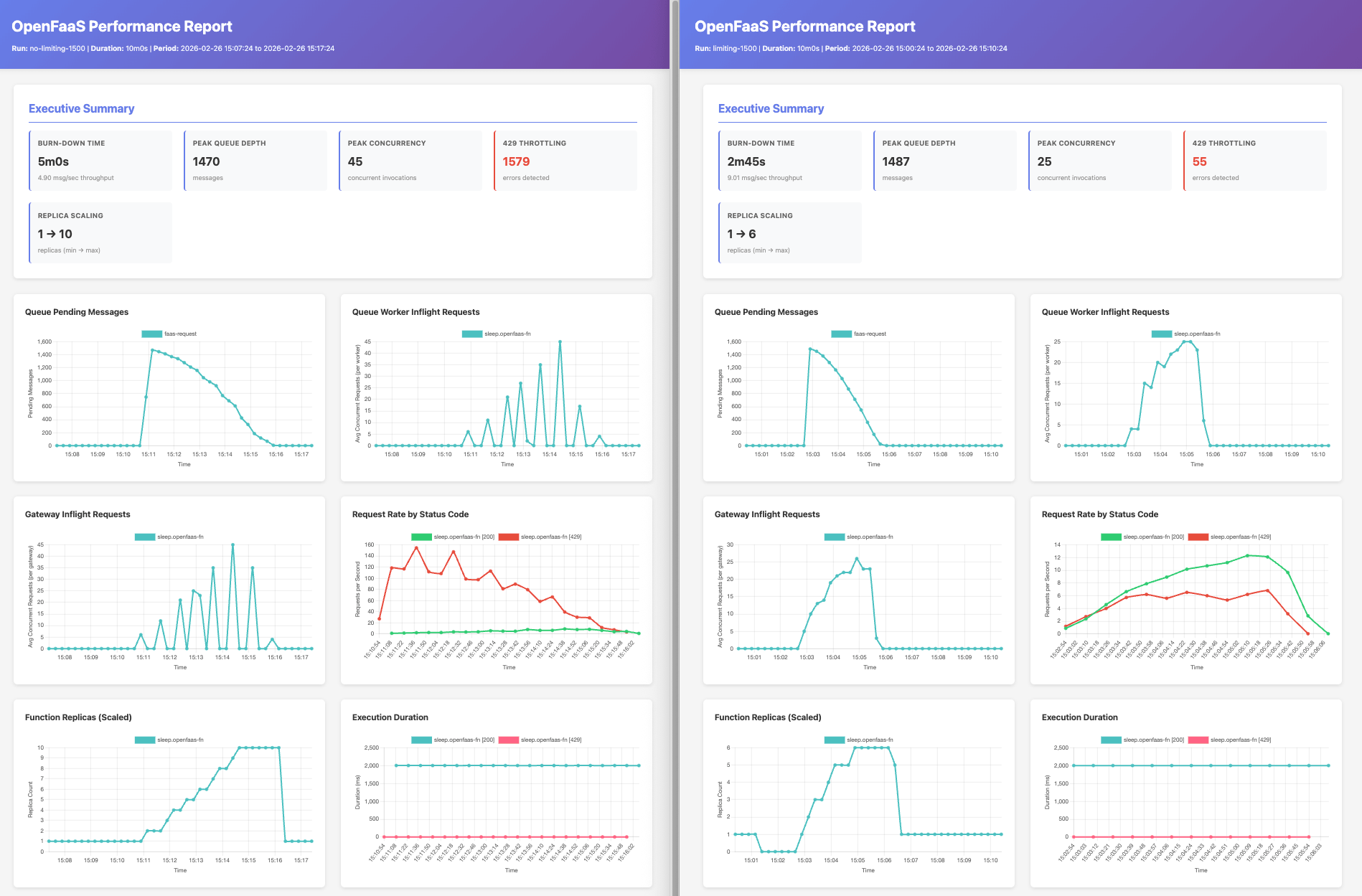
The key results:
- ~50% faster completion time — adaptive concurrency completed the same batch of work approximately 50% quicker than the greedy approach.
- Significantly fewer retries — with greedy dispatch, a large proportion of requests were retried (indicated by the rate of 429 responses in the Request Rate graph). Adaptive concurrency had far fewer, with the vast majority of requests completing on the first attempt.
- Consistent invocation load — instead of the burst-and-retry pattern visible with the greedy approach (Gateway Inflight Requests graph), adaptive concurrency maintained a more constant rate of in-flight requests, smoothly utilising available capacity.
- Lower overall resource usage — the greedy approach pushed the number of replicas higher in some tests due to the background noise from 429 retries inflating the perceived load on the system.
The fundamental insight is simple: the fewer the retries, the lower the cumulative exponential back-off time, and the shorter the overall processing time.
When to use adaptive concurrency
Adaptive concurrency helps whenever function capacity is limited — whether that limit is known upfront or varies at runtime. It works with any autoscaling mode (capacity, queue-based, RPS) and the queue-worker learns the capacity regardless of how replicas are being scaled.
Functions with a known concurrency limit
When a function has max_inflight set, each replica can only handle a fixed number of concurrent requests. This is the most common case and is ideal for:
- PDF generation — headless Chrome with Puppeteer can only run 1–2 browsers per replica
- ML inference — a GPU-bound model serving function where only one inference can run at a time (
max_inflight=1) - Video transcoding / image processing — CPU or memory-intensive work where each replica handles a small number of jobs
- Data ETL — batch processing pipelines where each step has a bounded throughput
The right max_inflight value depends on your function — it may require experimentation and monitoring to find the optimal setting. Once set, adaptive concurrency handles the rest.
Example: PDF generation at scale
In a previous post, Generate PDFs at scale on Kubernetes, we showed how to run headless Chrome with Puppeteer to generate hundreds of PDFs. Each replica can only run a small number of browsers at once, so max_inflight is set to 1 or 2. When a batch of 600 pages hits the queue, the greedy dispatch approach floods the function with requests, most of which are rejected with 429s. To get good results, you had to carefully tune the retry configuration — maxRetryWait, initialRetryWait, and maxRetryAttempts — and even then a large portion of the processing time was spent in exponential back-off.
With adaptive concurrency, the queue-worker learns that each replica can handle just one or two browsers and throttles dispatch to match. As replicas scale up, the concurrency limit rises automatically. The queue drains faster because requests aren’t wasted on retries, and you don’t need to tune retry parameters to get optimal throughput.
Functions with variable upstream capacity
Not every capacity limit is known in advance. Some functions depend on external resources that can slow down or become temporarily unavailable:
- Database-backed functions — a downstream database under heavy load starts timing out or rejecting connections
- Third-party API calls — an external service applies its own rate limiting or experiences degraded performance
- Shared upstream services — a microservice your function depends on is overloaded and responding slowly
In these cases, the function itself can return a 429 status code to signal back-pressure to the queue-worker. The adaptive concurrency algorithm responds the same way — it reduces the dispatch rate, waits, and probes for recovery. When the upstream resource recovers, the concurrency limit climbs back up automatically.
This means you don’t need max_inflight to benefit from adaptive concurrency. As long as your function returns 429 when it can’t handle more work, the queue-worker will adapt.
Try it out
Adaptive concurrency is enabled by default when using function mode in the JetStream queue-worker. If you’re already running function mode and you are on the latest OpenFaaS release, you’re using it.
Deploy a function with a concurrency limit and capacity-based autoscaling:
faas-cli store deploy sleep \
--label com.openfaas.scale.max=10 \
--label com.openfaas.scale.target=5 \
--label com.openfaas.scale.type=capacity \
--label com.openfaas.scale.target-proportion=0.9 \
--env max_inflight=5
Submit a batch of asynchronous invocations:
hey -m POST -n 500 -c 4 \
http://127.0.0.1:8080/async-function/sleep
Watch the Grafana dashboard for the queue-worker to see adaptive concurrency in action. You’ll see the concurrency limit climb as replicas scale up, then stabilise as capacity is matched.
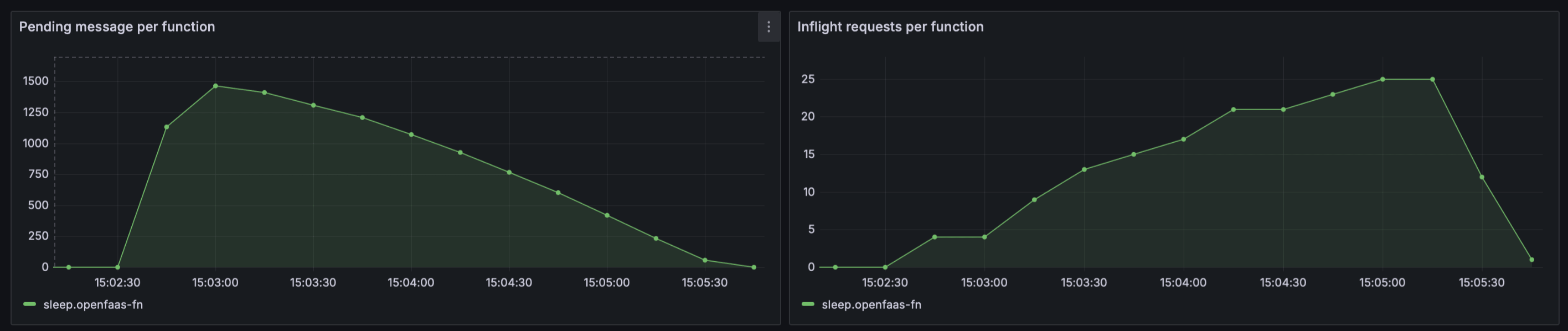
The queue depth drops steadily as the queue-worker increases inflight requests in step with available capacity — no sudden spikes or idle periods.
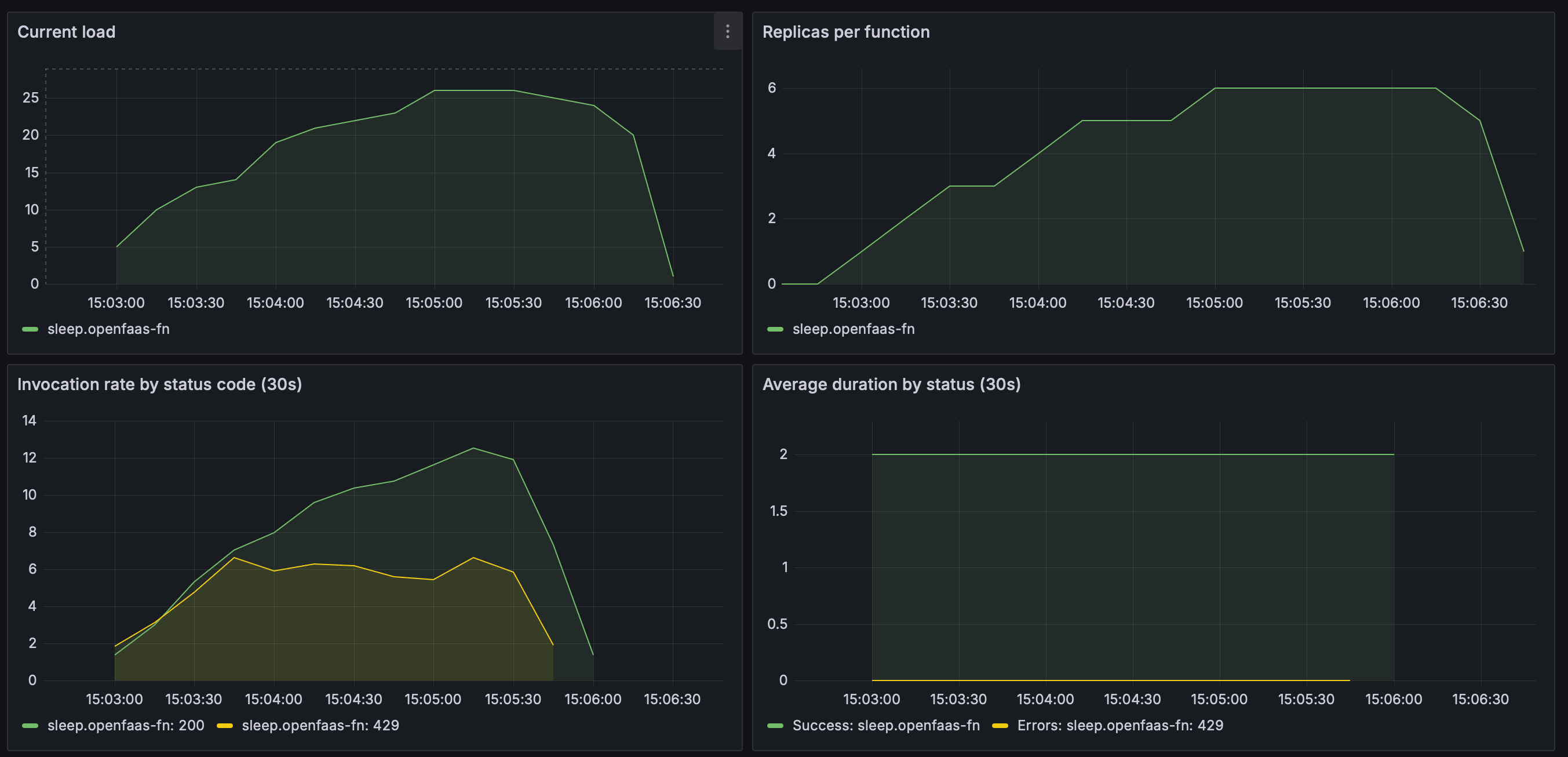
As replicas scale from 1 to 6, the in-flight load climbs smoothly to ~25. The
429response rate stays low throughout — the queue-worker throttles dispatch to match capacity rather than flooding the function with requests.
Further reading
- Queue Worker documentation — full reference for queue-worker configuration, including adaptive concurrency.
- Queue-Based Scaling for Functions — a complementary scaling mode that matches replicas to queue depth.
- Generate PDFs at scale on Kubernetes — a real-world example of batch processing with concurrency limits that benefits from adaptive concurrency.
- How to process your data the resilient way with back pressure — an introduction to back pressure and concurrency limits in OpenFaaS.
Wrapping up
The greedy dispatch algorithm has served OpenFaaS customers well and continues to be a reliable option. But for workloads with hard concurrency limits, adaptive concurrency is a meaningful improvement: it completes the same work faster by avoiding unnecessary retries, requires less per-function tuning, and makes better use of available capacity as functions scale up and down.
It’s enabled by default in function mode — no changes needed to start benefiting from it.
To disable adaptive concurrency and revert to greedy dispatch, set the following in your OpenFaaS Helm values:
jetstreamQueueWorker:
adaptiveConcurrency: false
If you have questions, or want to share results from your own workloads, reach out to us via your support channel of choice whether that’s Slack, the Customer Community on GitHub, or Email.

Han Verstraete
Associate Software Developer, OpenFaaS Ltd
