Learn how to scrape webpages using Puppeteer and Serverless Functions built with OpenFaaS.
Introduction to web testing and scraping
In this post I’ll introduce you Puppeteer and show you how to use it to automate and scrape websites using OpenFaaS functions.
There’s two main reasons you may want to automate a web browser:
- to run compliance and end-to-end tests against your application
- to gather information from a webpage which doesn’t have an API available
When testing an application, there are numerous options and these fall into two categories: rendered webpages, running with JavaScript and a real browser, and then text-based tests which can only parse static HTML. As you may imagine, loading a full web-browser in memory is a heavy-weight task. In a previous position I worked heavily with Selenium, which has language bindings for C#, Java, Python, Ruby and other languages. Whilst our team tried to implement most of our tests in the unit-testing layer, there were instances where automated web tests added value, and mean that the QA team could be involved in the development cycle by writing User Acceptance Tests (UATs) before the developers had started coding.
Selenium is still popular in the industry, and it inspired the W3C Working Draft of a Webdriver API that browsers can implement to make testing easier.
The other use-case is not to test websites, but to extract information from them when an API is not available, or does not have the endpoints required. In some instances, you see a mixture of both usecases, for instance - a company may file tax documents through a web-page using automated web-browsers, when that particular jurisdiction doesn’t provide an API.
Kicking the tires with AWS Lambda
I learned more recently of a friend who offers a search for Trademarks through his SaaS product, and for that purpose he chose a more modern alternative to Selenium called Puppeteer. In fact if you search StackOverflow or Google for “scraping and Lambda” you will likely see “Puppeteer” mentioned along with “headless-chrome.” I was curious to try out Puppeteer with AWS Lambda, and the path was less than ideal, with friction at almost every step of the way.
- The popular aws-chrome-lambda npm module is over 40MB in size because it ships a static binary binary, meaning it can’t be uploaded as a regular Lambda zip file, or as a Lambda layer
- The zip file needs to be uploaded through a separate AWS S3 bucket in the same region as the function
- The layer can then be referenced from your function.
- Local testing is very difficult, and there are many StackOverflow issues about getting the right combination of npm modules
I am sure that this can be done, and is being run at scale. It could be quite compelling for small businesses if they don’t spend too much time fighting the above, and can stay within the free-tier.
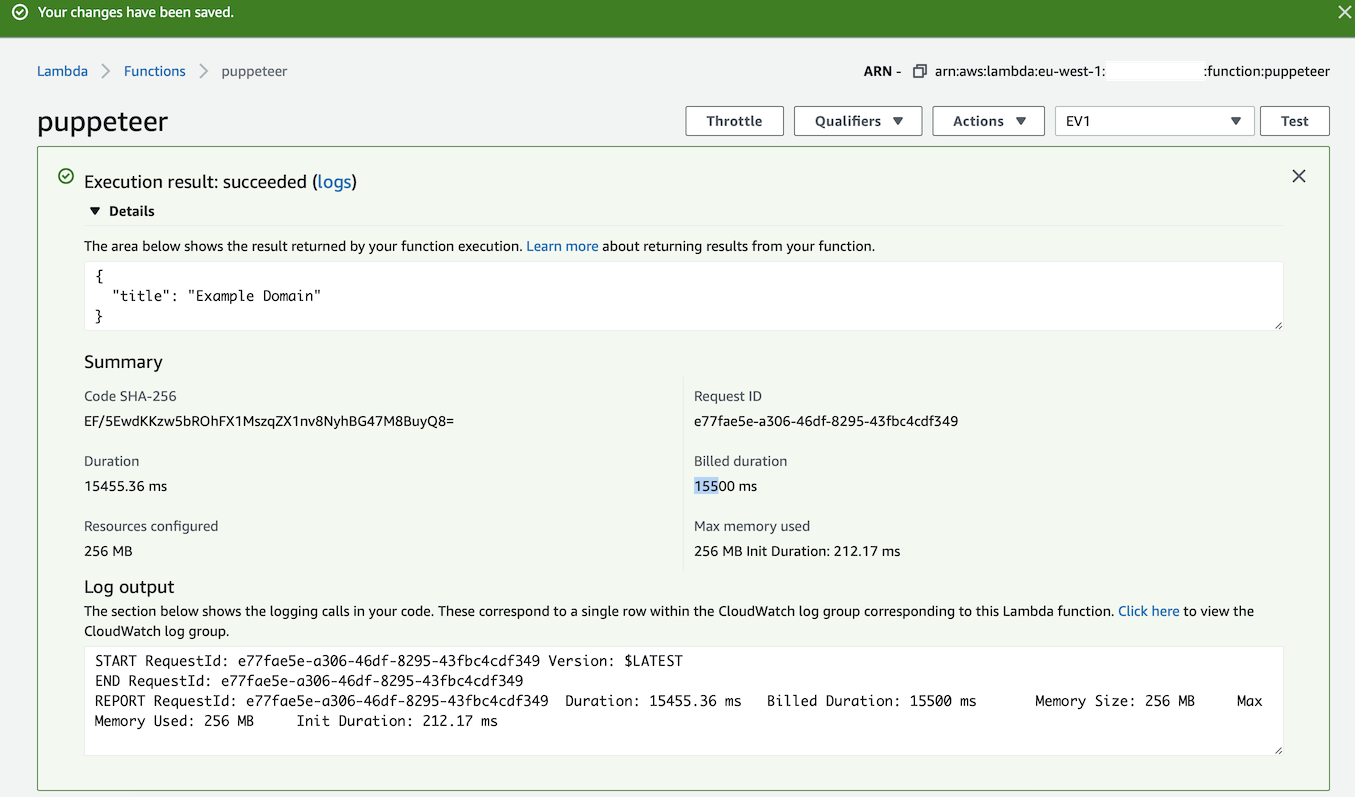
Getting the title of a simple webpage - 15.5s
That said, OpenFaaS can run anywhere, even on a 5-10 USD VPS and because OpenFaaS uses containers, it got me thinking.
Is there another way?
So I wanted to see if the experience would be any better with OpenFaaS. So I set out to see if I could get Puppeteer working with OpenFaaS, and this isn’t the first time I’ve been there. It’s something that I’ve come back to from time to time. Today, things seem even easier with a pre-compiled headless Chrome browser being available from buildkite.com.
Typical tasks involve logging into a portal and taking screenshots. Anecdotally, when I ran a simple test to navigate to a blog and take a screenshot, this took 15.5s in AWS Lambda, but only 1.6s running locally within OpenFaaS on my laptop. I was also able to build and test the function locally, the same way as in the cloud.
Walkthrough
We’ll now walk through the steps to set up a function with Node.js and Puppeteer, so that you can adapt an example and try out your existing tests that you may have running on AWS Lambda.
OpenFaaS features for web-scraping
What are the features we can leverage from OpenFaaS?
- Extend the function’s timeout to whatever we want
- Run the invocation asynchronously, and in parallel
- Get a HTTP callback with the result when done, such as a screenshot or test result in JSON
- Limit concurrency with
max_inflightenvironment variable in ourstack.yamlfile to prevent overloading the container - Trigger the invocations from cron, or events like Kafka and NATS
- Get rate, error and duration (RED) metrics from Prometheus, and view them in Grafana
OpenFaaS deployment options
We have made OpenFaaS as easy as possible to deploy on a single VM or on a Kubernetes cluster.
-
Deploy to a single VM if you are new to containers and just want to kick the tires whilst keeping costs low. This is also ideal if you only have a few functions, or are worried about needing to learn Kubernetes.
See also: Bring a lightweight Serverless experience to DigitalOcean with Terraform and faasd
-
This is the standard option we recommend for production usage. Through the use of containers and Kubernetes, OpenFaaS can be deployed and run at scale on any cloud.
Many cloud providers have their own managed Kubernetes services which means it’s trivial to get a working cluster. You just click a button and deploy OpenFaaS, then you can start deploying functions. The DigitalOcean and Linode Kubernetes services are particularly economic.
Deploy Kubernetes and OpenFaaS on your computer
In this post we’ll be running Kubernetes on your laptop, meaning that you don’t have to spend any money on public cloud to start trying things out. The tutorial should take you less than 15-30 minutes to try.
For the impatient, our arkade tool can get you up and running in less than 5 minutes. You’ll just need to have Docker installed on your computer.
# Get arkade, and move it to $PATH
curl -sLS https://get.arkade.dev | sh
sudo mv arkade /usr/local/bin/
# Run Kubernetes locally
arkade get kind
# Kubernetes CLI
arkade get kubectl
# OpenFaaS CLI
arkade get faas-cli
# Create a cluster
kind create cluster
# Install openfaas
arkade install openfaas
The arkade info openfaas command will print out everything you need to log in and get a connection to your OpenFaaS gateway UI.
Create a function with the puppeteer-node12 template
# Set to your Docker Hub account or registry address
export OPENFAAS_PREFIX=alexellis2
faas-cli template store pull puppeteer-nodelts
faas-cli new \
scrape-title \
--lang puppeteer-node12 \
--prefix $OPENFAAS_PREFIX
Let’s get the title of a webpage passed in via a JSON HTTP body, then return the result as JSON.
Now edit ./scrape-title/handler.js
'use strict'
const assert = require('assert')
const puppeteer = require('puppeteer')
module.exports = async (event, context) => {
let browser = await puppeteer.launch({
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-dev-shm-usage'
]
})
const browserVersion = await browser.version()
let page = await browser.newPage()
let uri = "https://inlets.dev/blog/"
if(event.body && event.body.uri) {
uri = event.body.uri
}
const response = await page.goto(uri)
let title = await page.title()
browser.close()
return context
.status(200)
.succeed({"title": title})
}
Deploy and test the scrape-title function
Deploy the scrape-title function to OpenFaaS.
faas-cli up -f scrape-title.yml
You can run faas-cli describe FUNCTION to get a synchronous or asynchronous URL for use with curl along with whether the function is ready for invocations. The faas-cli can also be used to invoke functions and we’ll do that below.
faas-cli describe scrape-title
Name: scrape-title
Status: Not Ready
Replicas: 1
Available replicas: 0
Invocations: 0
Image: alexellis2/scrape-title:latest
Function process: node index.js
URL: http://127.0.0.1:8080/function/scrape-title
Async URL: http://127.0.0.1:8080/async-function/scrape-title
Try invoking the function synchronously:
echo '{"uri": "https://inlets.dev/blog"}' | faas-cli invoke scrape-title \
--header "Content-type=application/json"
{"title":"Inlets PRO – Inlets – The Cloud Native Tunnel"}
Running with time curl was 10 times faster than my test with AWS Lambda with 256MB RAM allocated.
time curl http://127.0.0.1:8080/function/scrape-title --data-binary '{"uri": "https://example.com"}' --header "Content-type: application/json"
{"title":"Example Domain"}
real 0m0.727s
user 0m0.004s
sys 0m0.004s
Alternatively run async:
echo '{"uri": "https://inlets.dev/blog"}' | faas-cli invoke scrape-title \
--async \
--header "Content-type=application/json"
Function submitted asynchronously.
Run async, post the response to another service like requestbin or another function:
echo '{"uri": "https://inlets.dev/blog"}' | faas-cli invoke scrape-title \
--async \
--header "Content-type=application/json" \
--header "X-Callback-Url=https://enthao98x79id.x.pipedream.net"
Function submitted asynchronously.
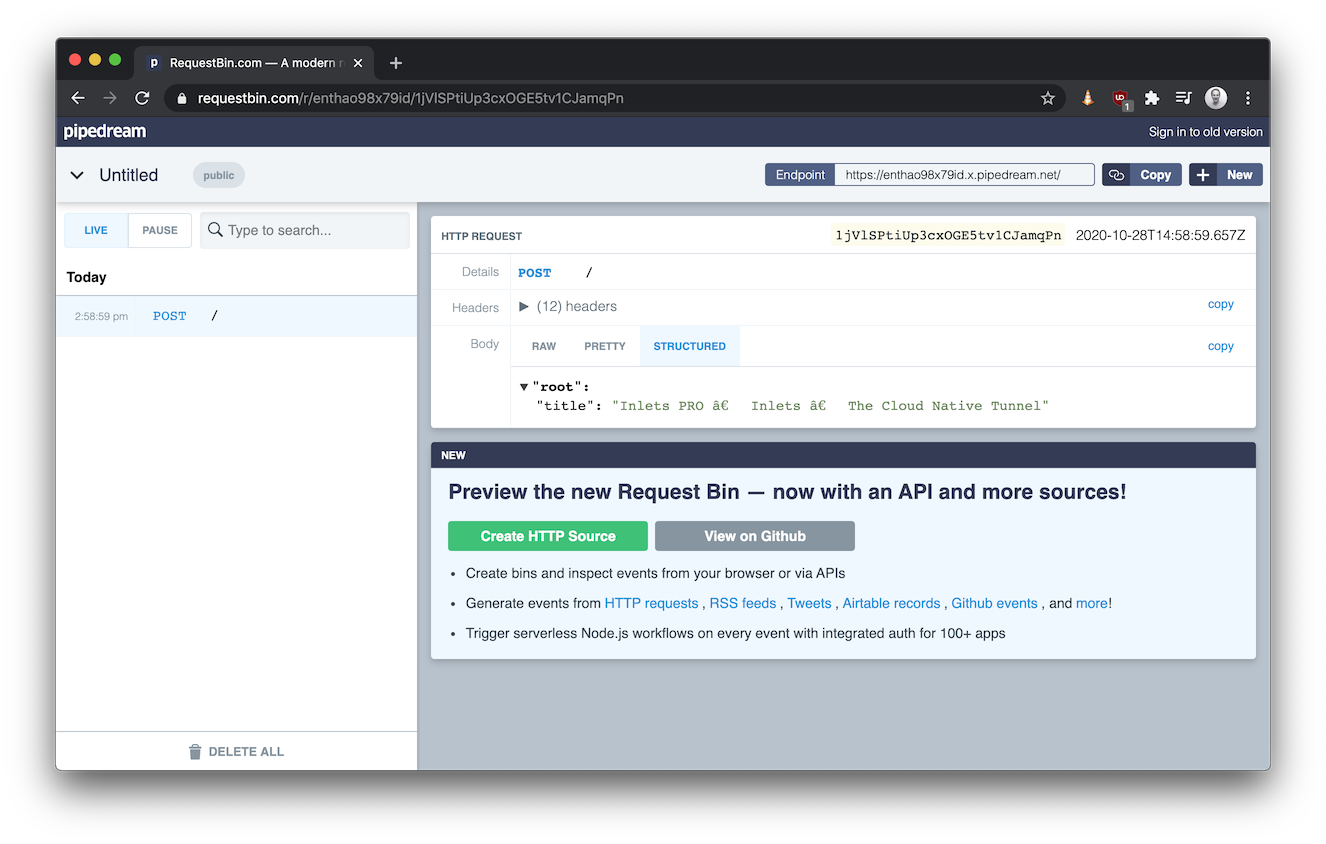
Example of a result posted back to RequestBin
Each invocation has a unique X-Call-Id header, which can be used for tracing and connecting requests to asynchronous responses.
Take a screenshot and return it as a PNG file
One of the limitations of AWS Lambda is that it can only return a JSON response, whilst there may be good reasons for this approach, OpenFaaS allows a binary input and response for functions.
Let’s try taking a screenshot of the page, and capturing it to a file.
# Set to your Docker Hub account or registry address
export OPENFAAS_PREFIX=alexellis2
faas-cli new --lang puppeteer-node12 screenshot-page --prefix $OPENFAAS_PREFIX
Edit ./screenshot-page/handler.js
'use strict'
const assert = require('assert')
const puppeteer = require('puppeteer')
const fs = require('fs').promises
module.exports = async (event, context) => {
let browser = await puppeteer.launch({
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-dev-shm-usage'
]
})
const browserVersion = await browser.version()
console.log(`Started ${browserVersion}`)
let page = await browser.newPage()
let uri = "https://inlets.dev/blog/"
if(event.body && event.body.uri) {
uri = event.body.uri
}
const response = await page.goto(uri)
console.log("OK","for",uri,response.ok())
let title = await page.title()
const result = {
"title": title
}
await page.screenshot({ path: `/tmp/page.png` })
let data = await fs.readFile("/tmp/page.png")
browser.close()
return context
.status(200)
.headers({"Content-type": "application/octet-stream"})
.succeed(data)
}
Now deploy the function as before:
faas-cli up -f screenshot-page.yml
Invoke the function, and capture the response to a file:
echo '{"uri": "https://inlets.dev/blog"}' | \
faas-cli invoke screenshot-page \
--header "Content-type=application/json" > screenshot.png
Now open screenshot.png and check the result.
Produce homepage banners and social sharing images
You can also produce homepage banners and social sharing images by rendering HTML locally, and then saving a screenshot.
Unlike a SaaS service, you’ll have no month fees to pay, and get unlimited use, you can also customise the code and trigger it however you like.
The execution time is very quick at under 0.5s per image and could be made faster by preloading the Chromium browser and re-using it. if you cache the images to /tmp/ or save them to a CDN, you’ll have single-digit latency.
# Set to your Docker Hub account or registry address
export OPENFAAS_PREFIX=alexellis2
faas-cli new --lang puppeteer-node12 banner-gen --prefix $OPENFAAS_PREFIX
Edit ./banner-gen/handler.js
'use strict'
const assert = require('assert')
const puppeteer = require('puppeteer')
const fs = require('fs');
const fsPromises = fs.promises;
module.exports = async (event, context) => {
let browser = await puppeteer.launch({
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-dev-shm-usage'
]
})
const browserVersion = await browser.version()
console.log(`Started ${browserVersion}`)
let page = await browser.newPage()
let title = "Set your title"
let avatar = "https://avatars2.githubusercontent.com/u/6358735?s=160&v=4"
console.log("query",event.query)
if(event.query) {
if(event.query.url) {
url = event.query.url
}
if(event.query.avatar) {
avatar = event.query.avatar
}
if(event.query.title) {
title = event.query.title
}
}
let html = `<html><body><h2>TITLE</h2><img src="AVATAR" alt="Avatar" width="120px" height="120px" /></body></html>`
html = html.replace("TITLE", title)
html = html.replace("AVATAR", avatar)
await page.setContent(html)
await page.setViewport({ width: 1720, height: 460 });
await page.screenshot({ path: `/tmp/page.png` })
let data = await fsPromises.readFile("/tmp/page.png")
await browser.close()
return context
.status(200)
.headers({"Content-type": "image/png"})
.succeed(data)
}
Deploy the function:
faas-cli up -f banner-gen.yml
Example usage:
curl -G "http://127.0.0.1:8080/function/generate-banner" \
--data-urlencode "avatar=https://avatars2.githubusercontent.com/u/6358735?s=160&v=4" \
--data-urlencode "title=Time for your favourite website to get social banners" \
-o out.png
Note that the inputs are URLEncoded for the querystring. You can also use the event.body if you wish to access the function programmatically, instead of from a browser.
This is an example image generated for my GitHub Sponsors page which uses a different HTML template, that’s loaded from disk.

HTML: sponsor-cta.html
Deploy a Grafana dashboard
We can observe the RED metrics from our functions using the built-in Prometheus UI, or we can deploy Grafana and access the OpenFaaS dashboard.
kubectl -n openfaas run \
--image=stefanprodan/faas-grafana:4.6.3 \
--port=3000 \
grafana
kubectl port-forward pod/grafana 3000:3000 -n openfaas
Access the UI at http://127.0.0.1:3000 and login with admin/admin.
See also: OpenFaaS Metrics
Hardening
If you’d like to limit how many browsers can open at once, you can set max_inflight within the function’s deployment file:
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
scrape-title:
lang: puppeteer-node12
handler: ./scrape-title
image: alexellis2/scrape-title:latest
environment:
max_inflight: 1
A separate queue can also be configured in OpenFaaS for web-scraping with a set level of parallelism that you prefer.
See also: Async docs
You can also set a hard limit on memory if you wish:
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
scrape-title:
lang: puppeteer-node12
handler: ./scrape-title
image: alexellis2/scrape-title:latest
limits:
memory: 256Mi
See also: memory limits
Long timeouts
Whilst a timeout value is required, this number can be as large as you like.
See also: Featured Tutorial: Expanded timeouts in OpenFaaS
Getting triggered
If you want to trigger the function periodically, for instance to generate a weekly or daily report, then you can use a cron syntax.
Users of NATS or Kafka can also trigger functions directly from events.
See also: OpenFaaS triggers
Wrapping up
You now have the tools you need to deploy automated tests and web-scraping code using Puppeteer. Since OpenFaaS can leverage Kubernetes, you can use auto-scaling pools of nodes and much longer timeouts than are typically available with cloud-based functions products. OpenFaaS plays well with others such as NATS which powers asynchronous invocations, Prometheus to collect metrics, and Grafana to observe throughput and duration and share the status of the system with others in the team.
The pre-compiled versions of Chrome included with docker-puppeteer and aws-chrome-lambda will not run on a Raspberry Pi or ARM64 machine, however there is a possibility that they can be rebuilt. For speedy web-scraping from a Raspberry Pi or ARM64 server, you could consider other options such as scrapy.
Ultimately, I am going to be biased here, but I found the experience of getting Puppeteer to work with OpenFaaS much simpler than with AWS Lambda, and think you should give it a shot.
Find out more:

Alex Ellis
Founder of @openfaas.
