Learn how to trigger OpenFaaS functions whenever rows change in your PostgreSQL databases.
Events and invocations
OpenFaaS functions are triggered by invoking them over HTTP - either synchronously or asynchronously. When some people hear this, they start to wonder where events and various types of triggers fit it.
Well, the pattern we’ve built and that’s used with customers in production today involves writing an event connector which can bind to a source of events. That’s part one. Part two is getting the connector to invoke the right functions whenever an event is received, through the gateway, over HTTP. Part three is much more nuanced and involves scaling, security, observability, and packaging.
We already have several mature event connectors available like:
- The Kafka connector - for integrating with existing systems
- The AWS SQS connector - for integrating with any kind of event that AWS can produce, or events from your own code on AWS
- The Cron connector - invoke functions upon a schedule
Event connectors can be combined for where you may invoke a function through Kafka for live notifications, but also invoke it via cron on a periodic basis to pick up any additional work that needs to be processed.
The new Postgresql connector
We recently released a new connector for PostgreSQL. With this connector OpenFaaS functions can be triggered whenever changes are made to a database table. We’ve done work in the past with triggering functions from databases, so when Greg Burd at Klar.mx who’d just migrated to OpenFaaS Pro asked for help, we set some time aside and built this connector for his team.
Greg inherited a large series of microservices written in Python and Java, along with dozens of database tables which had been used to store data over a long period of time.
Quite simply, he needed to invoke functions whenever a certain table had rows inserted or updated, and wanted a better alternative than periodically polling the database with a query.
You can also use this connector to make Postgresql feel more event-driven, if you haven’t already adopted an event bus like Apache Kafka.
How does it work?
There are two modes available, one uses the Write Ahead Log (WAL), and the other uses a generic trigger that can be bound to various tables on an independent basis. We expect most people to use the WAL mode, but Klar had specific requirements, so we introduced the generic trigger for them.
- See the full list of available connectors
- Learn more about WAL in Postgresql
How to Trigger functions from AWS Aurora PostgreSQL
In this section we will show you how to configure an AWS Aurora PostgreSQL database and the OpenFaaS Pro Postgres connector to trigger functions from database events.
Most of the steps should be very similar if you are using another managed PostgreSQL service or if you are self hosting your database. You’ll most likely only need to adapt the database configuration steps.
Provision AWS Aurora Postgresql database
Amazon Aurora PostgreSQL is a fully managed, PostgreSQL–compatible database. You can create a new database using the RDS console.
There are two things we need to take into account when creating the database cluster:
- The database has to be publicly accessible so we can connect to it from the OpenFaaS cluster.
- The DB cluster must be configured to use a custom DB cluster parameter group so that we can set the necessary configuration parameters to enable logical replication.
Before you create the database cluster create a new parameter group:
- In the RDS console, under ‘Parameter groups’ create a new parameter group.
-
Make sure to select
aurora-postgresqlfor the ‘Parameter group family’ field and select ‘DB Cluster Parameter Group’ as the type.
- After creating the new parameter group use the search field to find the
rds.logical_replicationfield and set it to 1 to enable logical replication. You may need to change other parameters likemax_replication_slotsandmax_wal_sendersas specified in the OpenFaaS docs. For this tutorial the default values are sufficient.
Next create a new Aurora PostgreSQL database cluster:
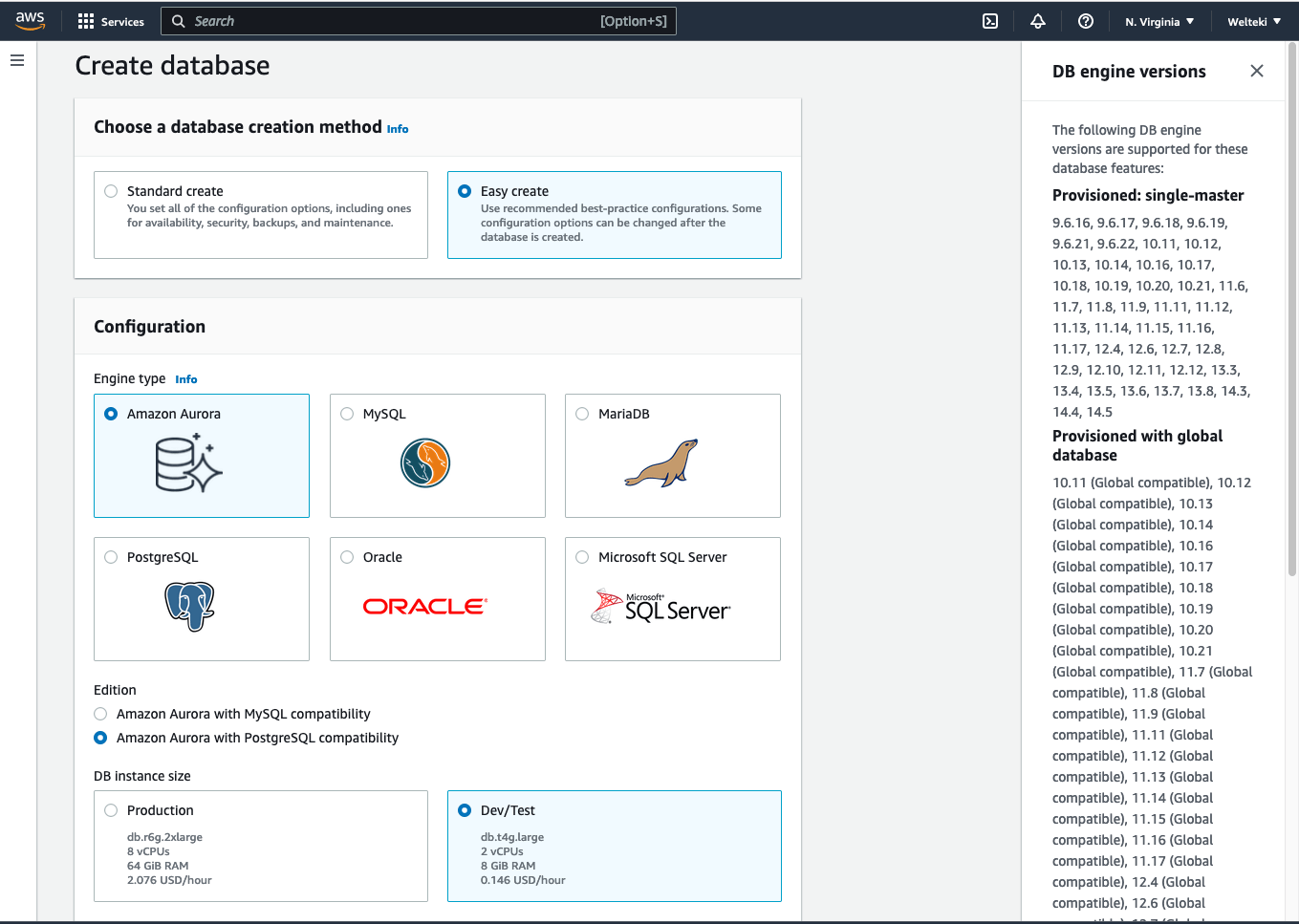
You can use the easy create option and update the following settings after creating the database or select the standard create mode:
- Under ‘Connectivity’ make sure
yesis selected for public access. - Under ‘Database options’ in the ‘Additional configuration’ panel select the DB cluster parameter group you created.
After creating your database save the master username and the master password. They will be needed later to connect to the database with psql and to compose the connection string for the postgres-connector.
To allow public access to the database add the source public IP address that you want to connect to the DB instance from in the inbound rules for the security group used by the DB.
When creating an Amazon Aurora DB cluster using the AWS Management Console, Amazon RDS automatically creates a VPC for you. You can modify the default VPC security group for your databases VPC in the VPC console.
For a more detailed explanation see: How can I configure private and public Aurora endpoints in the Amazon RDS console?
Install the OpenFaaS Pro Postgres connector
Save the connection string for your postgres database to a file postgresql-connection.txt. Use the master username and password you saved earlier while provisioning the database. You might need to URL encode the password if it contains any reserved or unsafe characters.
postgresql://USER:PASSWORD@your-db-cluster.aws-region.rds.amazonaws.com:5432/postgres
Note that if your password contains special characters, you may need to URL encode it first with the following Python code:
# pip install urllib
>>> import urllib.request as urllib2
>>> urllib2.quote(u"Grønlandsleiret".encode('UTF-8'))
You can lookup the endpoint for your database in the RDS console. Select your database cluster from the databases tab and look at the endpoints table under ‘Connectivity & security’.
Run the following to create a secret for the connection string that can be used by the Postgres connector:
kubectl create secret generic -n openfaas \
postgresql-connection --from-file postgresql-connection=./postgresql-connection.txt
Create a pgconnector.yaml file to use with helm:
# filter notifications
filters: "customer:insert,customer:update"
# Use logical replication and the write-ahead log (WAL)
wal: true
The filters parameter can be used to filter which tables and events to be notified about. A filter should be formatted as tablename:action. The action can be one of: insert, update, delete.
Now deploy the connector using the Helm chart:
$ helm repo add openfaas https://openfaas.github.io/faas-netes/
$ helm repo update
$ helm upgrade postgres-connector openfaas/postgres-connector \
--install \
--namespace openfaas \
-f pgconnector.yaml
You can check the logs to verify the connector is running and connected to the database:
$ kubectl logs -n openfaas deploy/postgres-connector -f
OpenFaaS postgres-connector Pro Version: 0.0.4 Commit: 826662203309115ea37427fdd1d638d0b91386fa
2022/12/08 17:48:29 Licensed to: Han Verstraete <han@openfaas.com>, expires: 25 day(s) Products: [inlets-pro openfaas-pro]
2022/12/08 17:48:30 Publication "ofltd" exists
2022/12/08 17:48:30 Log Sequence Number: 2348812208
Trigger a function
The printer function can be used to help with testing and debugging function invocations. It prints out the HTTP headers and body of any invocation.
Deploy it use the faas-cli to deploy it:
faas-cli store deploy printer \
--annotation topic=customer:insert,customer:update
The annotation topic is required so that the connector can link the function to the events. In this case the connector will invoke the printer function every time a record in the customer table is inserted or updated.
You can use psql to connect to your database and create a table for testing the postgres connector:
-
Connect to the database.
psql --host=your-db-cluster.aws-region.rds.amazonaws.com \ --port=5432 \ --username=postgres \ --password \ --dbname=postgres -
Use the following SQL statement to create a table.
CREATE TABLE customer (id integer primary key generated always as identity, name text, created_at timestamp);Inserting a new record into the table should trigger our function. To insert a new record run:
INSERT INTO customer (name, created_at) VALUES ('Alex Ellis', now());
Get the logs from the printer function and see that it received a message. The output should look like like this:
$ faas-cli logs printer
2022-12-12T11:48:27Z X-Event-Table=[customer]
2022-12-12T11:48:27Z X-Message-Id=[0]
2022-12-12T11:48:27Z Accept-Encoding=[gzip]
2022-12-12T11:48:27Z X-Start-Time=[1670845707036086529]
2022-12-12T11:48:27Z Content-Type=[application/json]
2022-12-12T11:48:27Z X-Call-Id=[3743db89-1316-486b-bfb3-7e162c1b678f]
2022-12-12T11:48:27Z X-Forwarded-For=[10.42.1.176:49326]
2022-12-12T11:48:27Z X-Topic=[customer:insert]
2022-12-12T11:48:27Z User-Agent=[Go-http-client/1.1]
2022-12-12T11:48:27Z X-Connector=[connector-sdk openfaasltd/postgres-connector]
2022-12-12T11:48:27Z X-Event-Action=[insert]
2022-12-12T11:48:27Z X-Event-Id=[80d70c86-cdf0-4791-958c-ef9d04e73a26]
2022-12-12T11:48:27Z X-Forwarded-Host=[gateway.openfaas:8080]
2022-12-12T11:48:27Z
2022-12-12T11:48:27Z {"id":"80d70c86-cdf0-4791-958c-ef9d04e73a26","schema":"public","table":"customer","action":"insert","data":{"id":10,"name":"Alex Ellis","created_at":"2022-12-12 11:48:26.965465"},"commitTime":"2022-12-12T11:48:26.970059Z"}
2022-12-12T11:48:27Z
2022-12-12T11:48:27Z 2022/12/12 11:48:27 POST / - 202 Accepted - ContentLength: 0B (0.0010s)
We can see that we get some useful data about the event source in the headers as well as in the json body. The message body also contains the records data.
A full reference of the available headers and message structure can be found in the documentation.
Use multiple connectors
It is possible to trigger the same function from multiple event sources. The topics for the different connecters can just be added to the topic annotation as a comma separated list.
In this example we deploy a function that can be trigger by both the Cron connector and the Postgres connector:
faas-cli store deploy printer \
--annotation topic=cron-function,customer:insert \
--annotation schedule="*/5 * * * *"
Note: Using multiple connectors is only supported by OpenFaaS Pro connectors. Make sure to use the Pro version of the Cron connector. It can be deployed by setting the parameter
openfaasPro=true. See the Cron connector Helm chart.
Conclusion
We’ve set up a PostgreSQL database with AWS Aurora and configured OpenFaaS Pro to dispatch messages to our functions when there are changes to a database table. Triggering functions from your database allows you to run background jobs on database changes or it can be used to quickly extend an existing application.
Future work
We’re also considering introducing predicates for all OpenFaaS connectors. There are two use cases here:
- Filtering out data from large payloads, for the case where you only need to receive the primary key from a table, or just a few fields. You may also want to mutate data, for instance to redact all but the last 4 digits of a credit card number.
- Reducing the number of invocations through a simple expression
In the first case, you may imagine that we’d add a basic transformation written in Python into an annotation like this, where you may have 100 different fields, but only need two as an input to the function: return {k: v for (k, v) in data.items() if k in ["id","status"] }.
For the second case, you may potentially have a rule like this: data["status"] == "settled", where you only want to have a function invoked when a customer’s bill changes to from any other status to “settled”.
If you think either of these cases would save you time and make your functions perform better, please feel free to reach out to us.
Next steps
If you have questions, please check out the Postgres events page in the docs, or feel free to get in touch.
Make sure to take a look at the other triggers available for OpenFaaS
You may also like:
- Staying on topic: trigger your OpenFaaS functions with Apache Kafka
- Event-driven OpenFaaS with Managed Kafka from Aiven

Han Verstraete
Associate Software Developer, OpenFaaS Ltd
