We show you how to process huge amounts of data in parallel through fanning out, then how to fan back in to consolidate the results.
Functions are a natural fit for processing data because they’re short-lived, stateless, and can scale out efficiently to process large amounts of data.
Fanning out: A common pattern for processing large amounts of data is to break down an expensive task into smaller sub tasks that can be executed in parallel. This fan-out pattern is already available in OpenFaaS through asynchronous functions. With the async, the various invocations are queued up and processed as and when there’s capacity available.
In a previous article, we showed you how to process large amounts of data both asynchronously and reliably with the fan-out pattern: How to process your data the resilient way with back pressure .
The MapReduce pattern was popularised by Apache Hadoop, which specialises in processing large batches of data. One dataset or task is split into many others, which can be worked on in parallel over a large distributed network of computers, that’s the map step. The reduce step is where the results are combined to make sense of them. We’ll cover the basics of the two stages in the tutorial, of fanning out and fanning back in again.
Fanning back in: We’ve seen customers making use of OpenFaaS not only to fan out requests, but to consolidate them through fanning back in, so we wanted to show you how we think it can be done without making any changes to OpenFaaS itself.
In this article, you’ll find a deeper dive into fanning in and out, code examples, along with insights on how to monitor OpenFaaS to see how quickly and efficiently your data is being worked on.
The fan-out pattern
Fan-out can be used to split a larger task or batch of tasks into smaller sub tasks. The processing of each sub task is deferred to another function. These functions can run in parallel to complete all tasks as quickly and efficiently as possible.
The fan-out pattern is already supported in OpenFaaS through the asynchronous invocation system
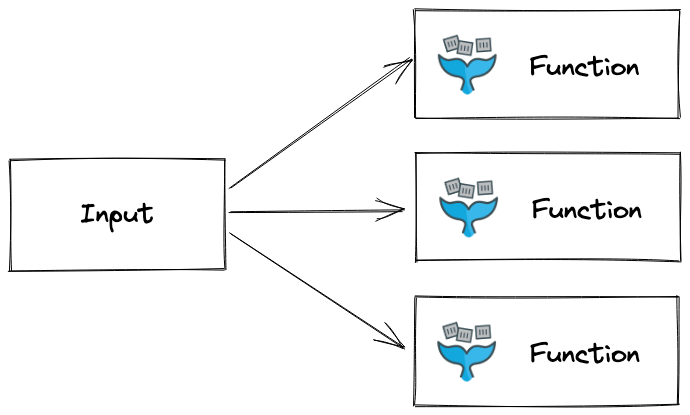
Diagram of fan-out with functions
The fan-in pattern
The fan-in pattern can be applied if you need to wait for all sub tasks to complete before moving on to the next processing step. It can be used to collect and combine the result from each individual sub task.
To fan-in, some kind of shared storage, like a database, a Redis key or an S3 bucket is required for tracking progress of the individual sub tasks.
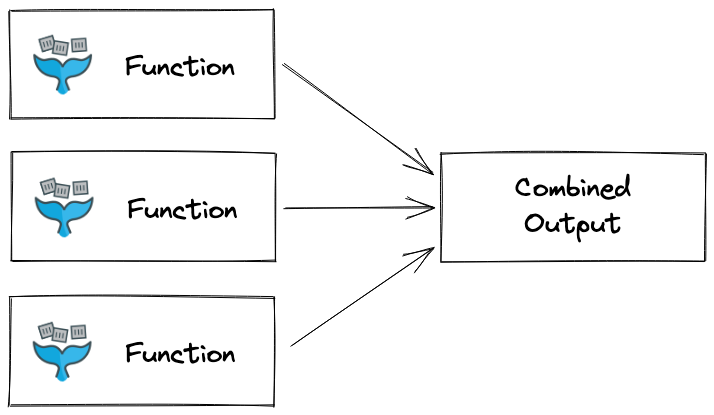
Diagram of fan-in with functions
Implement a fan-out/fan-in pattern in OpenFaaS.
In this section we are going to show you how this pattern can be implemented with OpenFaaS through a relatable use-case. A common big data scenario is batch processing of a data set. In this scenario data is retrieved from a storage system and then processed by parallelized jobs. The result of each individual job is persisted in some kind of data store where it can later be retrieved for further processing when the batch is completed.
In this example we are going to process a CSV file containing URLs to images on Wikipedia. For each URL in the data set we want to run the Inception model and get back image categorizations through machine learning. The inception model can classify what’s in a photo based upon a training set made up of objects and animals. As a final processing step we will combine all the individual results into a single output.
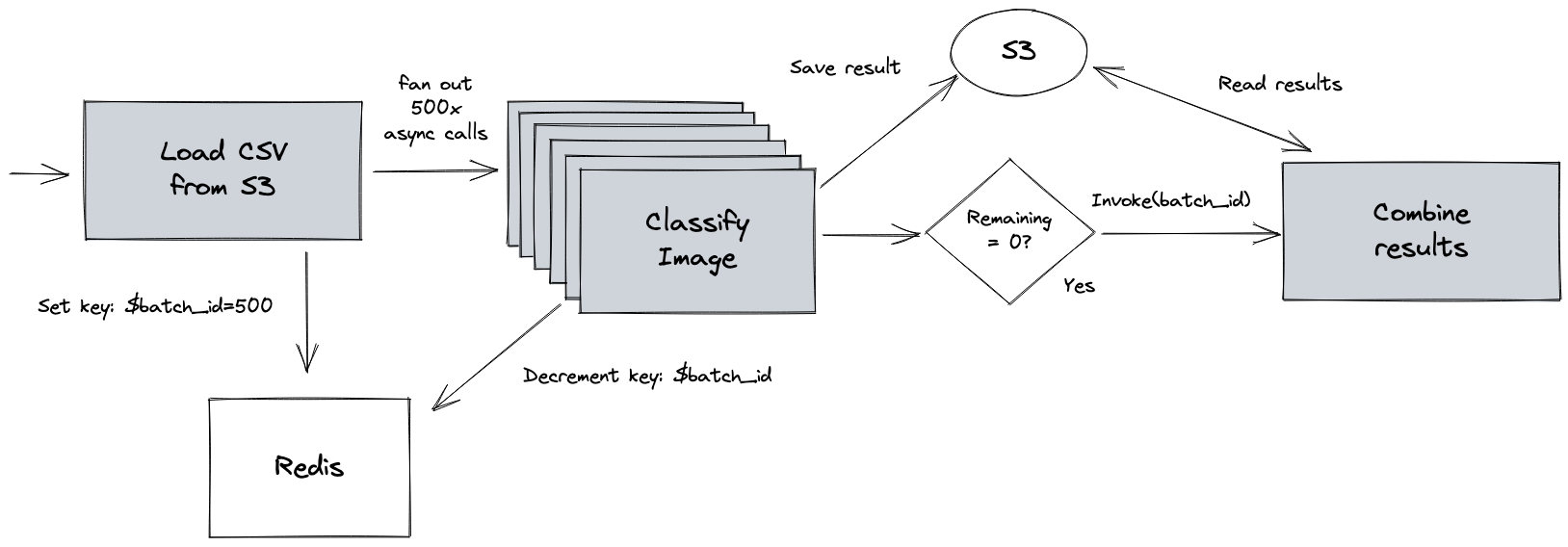
Fan-out/fan-in pattern with OpenFaaS functions
You can find the full example on GitHub
Fan-out
S3 will be used as the data store throughout this example. The input files are retrieved from an S3 bucket, results of invocations and the final result will be uploaded to the same bucket. To run this example yourself you will need to create an Amazon S3 bucket.
The functions need access to AWS credentials in order to use the bucket. Save your AWS access key Id and secret in separate files and use the faas-cli to create two new OpenFaaS secrets.
faas-cli secret create s3-key --from-file aws_access_key_id.txt
faas-cli secret create s3-secret --from-file aws_secret_access_key.txt
You can checkout the documentation for more info on how to use secrets within your functions.
The first part of the workflow will consist of two functions. The create-batch function is responsible for initialising the workflow. It accepts the name of a CSV file stored in an S3 bucket as input. The function will retrieve the CSV file containing image URLs and invoke the second function, run-model for each URL in the file.
The run-model function is responsible for calling the machine learning model, in this case the inception function, and uploading the result to S3.
We will use the python3-http template for both functions. It is available from the python3-flask store template:
# Get the python3-flask template from the store
faas-cli template store pull python3-flask
# Scaffold the functions
faas-cli new create-batch --lang python3-http-debian
faas-cli new run-model --lang python3-http -f stack.yaml
Note that we use python3-http-debian for the create-batch function. pandas will be used to process the CSV file. The pandas pip module requires a native build toolchain. It is advisable to use the Debian version of the template for native dependencies.
All dependencies have to be put into the requirements.txt file.
We will use a pre-build function image for the inception function. Add the function to the stack.yaml file:
functions:
inception:
image: alexellis2/imagenet:0.0.12
skip_build: true
environment:
read_timeout: "60s"
write_timeout: "60s"
# OpenFaaS Pro annotations
annotations:
com.openfaas.ready.http.path: "/ready"
com.openfaas.ready.http.initialDelay: "5s"
com.openfaas.ready.http.periodSeconds: "2s"
The skip_build field tells the CLI to not attempt to build the Docker image for this function.
The function needs to load the ML model before it can start accepting requests. Annotations are used to configure a custom readiness check on the /ready endpoint. This will prevent requests from being sent to the function before it is ready to accept them. You can take a look at the source code of the imagenet function to see how this is implemented.
For an in depth overview on readiness and health checks take a look at our blog post: Custom health and readiness checks for your OpenFaaS Functions
The requirements.txt file for the create-batch function:
requests
pandas
smart_open[s3]
The handler of the create-batch functions:
import os
import json
import uuid
import requests
import pandas as pd
import boto3
from smart_open import open
s3Client = None
def initS3():
with open('/var/openfaas/secrets/s3-key', 'r') as s:
s3Key = s.read()
with open('/var/openfaas/secrets/s3-secret', 'r') as s:
s3Secret = s.read()
session = boto3.Session(
aws_access_key_id=s3Key,
aws_secret_access_key=s3Secret,
)
return session.client('s3')
def handle(event, context):
global s3Client
# Initialise an S3 client upon first invocation
if s3Client == None:
s3Client = initS3()
bucketName = os.getenv('s3_bucket')
# Get the data set from S3
batchFile = event.body.decode()
s3URL = 's3://{}/{}'.format(bucketName, batchFile)
with open(s3URL, 'rb', transport_params={'client': s3Client }) as f:
records = pd.read_csv(f)
batchId = str(uuid.uuid4())
batchSize = len(records)
# Fan-out by invoking the run-model function asynchronously
for index, col in records.iterrows():
headers = { 'X-Batch-Id': batchId }
res = requests.post('http://gateway.openfaas:8080/async-function/run-model', data=col['url'], headers=headers)
response = {
'batch_id': batchId,
'batch_size': batchSize
}
return {
"statusCode": 201,
"body": json.dumps(response)
}
At the start of the function the S3 credentials are read, and the name of the bucket is passed in using an env variable. Make sure the correct secrets and env variables are added to the stack.yaml configuration for each function.
functions:
create-batch:
lang: python3-http-debian
handler: ./create-batch
image: welteki2/create-batch:latest
environment:
- s3_bucket: of-demo-inception-data
secrets:
- s3-key
- s3-secret
The S3 client is created and stored in a global variable upon the first request. Creating a S3 client in the handler for each request is quite an expensive operation. By initialising it once and assigning it to a global variable it can be reused between function invocations. The first version of this example did not reuse the clients. By moving them to the outer scope we managed to reduce the average call duration of the run-model function by 1s.
The function then reads the name of the CSV file from the body and that file name is used to retrieve the input data from S3. We then iterate over each row in the input CSV file and invoke the run-model function for each URL in the file. Note that run-model is invoked asynchronously. This decouples the HTTP transaction between the caller and the function. The request is added to a queue and picked up by the queue-worker to run it in the background. This allows us to run the multiple invocations in parallel.
The parallelism of a batch job can be controlled by changing the number of tasks the queue-worker runs at once. See our official documentation for more details on how to do this.
The requirements.txt file for the run-model function:
requests
smart_open[s3]
The handler for the run-model function:
import os
import json
import requests
import boto3
from smart_open import open
s3Client = None
def initS3():
with open('/var/openfaas/secrets/s3-key', 'r') as s:
s3Key = s.read()
with open('/var/openfaas/secrets/s3-secret', 'r') as s:
s3Secret = s.read()
session = boto3.Session(
aws_access_key_id=s3Key,
aws_secret_access_key=s3Secret,
)
return session.client('s3')
def handle(event, context):
global s3Client
# Initialise an S3 client upon first invocation
if s3Client == None:
s3Client = initS3()
bucketName = os.getenv('s3_bucket')
batchId = event.headers.get('X-Batch-Id')
url = event.body.decode()
# Run the machine learning model and store the result in S3
res = requests.get("http://gateway.openfaas:8080/function/inception", data=url)
callId = res.headers.get('X-Call-Id')
status = 'success' if res.status_code == 200 else 'error'
result = res.json() if res.status_code == 200 else res.text
taskResult = {
'batchId': batchId,
'callId': callId,
'url': url,
'result': result,
'status': status
}
fileName = '{}/{}.json'.format(batchId, callId)
s3URL = "s3://{}/{}".format(bucketName, fileName)
with open(s3URL, 'w', transport_params={'client': s3Client }) as fout:
json.dump(taskResult, fout)
return {
"statusCode": 200,
"body": "Success running model"
}
The run-model function invokes the inception function synchronously and stores the result, along with some metadata like the batch id, call id, and status, as a json file in S3. The result is stored in a folder named after the batch id. This makes it easy to retrieve all results for a certain batch. The metadata can be useful for debugging or when processing the data in a later step.
Fan-in
To be able to fan-in and get notified when all the asynchronous invocations for a batch have finished we need some state to keep track of the progress. A counter can be used to keep track of the work that has been completed. Each time an asynchronous invocation finishes the counter is decremented. When the counter reaches zero the final function in the workflow can be called.
We are going to use a Redis key to store this state for each batch. It has a DECR command to atomically decrement a value and it returns the new key value at the end.
arkade offers you a convenient way to deploy Redis:
arkade install redis
After the installation is completed, fetch the password and create a secret for it so that it can be used within the functions.
export REDIS_PASSWORD=$(kubectl get secret --namespace redis redis -o jsonpath="{.data.redis-password}" | base64 --decode)
echo $REDIS_PASSWORD | faas-cli secret create redis-password
We need to create a Redis client in the create-batch and run-model functions that they can use to initialise and update the counter.
The following code creates a connection to Redis using redis-py:
redisClient = None
def initRedis():
redisHostname = os.getenv('redis_hostname')
redisPort = os.getenv('redis_port')
with open('/var/openfaas/secrets/redis-password', 'r') as s:
redisPassword = s.read()
return redis.Redis(
host=redisHostname,
port=redisPort,
password=redisPassword,
)
Initialize the redis client in the function handler:
def handle(event, context):
global redisClient
if redisClient == None:
redisClient = initRedis()
Update the stack.yaml for the functions to add the Redis environment variables and secret:
environment:
s3_bucket: of-demo-inception-data
redis_hostname: "redis-master.redis.svc.cluster.local"
redis_port: 6379
secrets:
- s3-key
- s3-secret
- redis-password
Don’t forget to add redis to the requirements.txt for your functions.
The create-batch function can now be updated to count the number of URLs in the CSV file and initialize a Redis key for batchId with that value.
batchFile = event.body.decode()
s3URL = 's3://{}/{}'.format(bucketName, batchFile)
with open(s3URL, 'rb', transport_params={'client': session.client('s3')}) as f:
records = pd.read_csv(f)
batchId = str(uuid.uuid4())
batchSize = len(records)
# Initialize a counter in Redis
redisClient.set(batchId, batchSize)
for index, col in records.iterrows():
headers = { 'X-Batch-Id': batchId }
res = requests.post('http://gateway.openfaas:8080/async-function/run-model', data=col['url'], headers=headers)
In the run-model function we need to decrement this counter every time an invocation to the inception function finishes. If the counter reaches zero, this means all work in the batch is completed and the final function can be invoked.
remainingWork = redisClient.decr(batchId)
if remainingWork == 0:
headers = { 'X-Batch-Id': batchId }
res = requests.post("http://gateway.openfaas:8080/async-function/collect-result", headers=headers)
r.delete(batchId)
Collect the results
The final function is called when all asynchronous requests in a batch are completed. This function can be used to aggregate the results, notify some other actor or trigger the next step in your processing workflow. In this example we are going to use it to collect all the responses in a single json file and upload that file to the S3 bucket.
The code of the collect-result function:
import os
import json
import boto3
from smart_open import s3
from smart_open import open
s3Client = None
s3Key = None
s3Secret = None
bucketName = os.getenv('s3_bucket')
def initS3():
global s3Key, s3Secret
with open('/var/openfaas/secrets/s3-key', 'r') as s:
s3Key = s.read()
with open('/var/openfaas/secrets/s3-secret', 'r') as s:
s3Secret = s.read()
session = boto3.Session(
aws_access_key_id=s3Key,
aws_secret_access_key=s3Secret,
)
return session.client('s3')
def handle(event, context):
global s3Client
if s3Client == None:
s3Client = initS3()
batchId = event.headers.get('X-Batch-Id')
passed = []
failed = []
for key, content in s3.iter_bucket(bucketName, prefix=batchId + '/', workers=30, aws_access_key_id=s3Key, aws_secret_access_key=s3Secret):
data = json.loads(content)
if (data['status'] == 'error'):
failed.append({ 'url': data['url'], 'result': data['result'] })
else:
passed.append({ 'url': data['url'], 'result': data['result'] })
summary = {
'batchId': batchId,
'failed': {
'count': len(failed),
'results': failed
},
'passed': {
'count': len(passed),
'results': passed,
}
}
fileName = 'output.json'
s3URL = "s3://{}/{}/{}".format(bucketName, batchId, fileName)
with open(s3URL, 'w', transport_params={'client': s3Client }) as fout:
json.dump(summary, fout)
return {
"statusCode": 200,
"body": 'Processed batch: {}'.format(batchId)
}
The function retrieves the batch id from the http headers and uses it to iterate over the S3 Bucket’s Contents. All results for the specific batch are read and added to the summary. As a final step the summary file called output.json is uploaded to the output folder for the batch.
When processing a large batch this function can take a while to complete. Make sure that your timeouts are configured correctly for both your function and the OpenFaaS core components. See: Expanding timeouts
Process a batch
You can find some CSV files containing links to Wikipedia images in the data folder on GitHub
The create-batch function looks for the input files in the S3 bucket. Upload them to your S3 bucket.
aws s3 cp data/batch-1000.csv s3://of-demo-inception-data/data/batch-1000.csv
Invoke the function create-batch with the name of the source file you want to start processing.
curl -i http://127.0.0.1:8080/function/create-batch -d data/batch-1000.csv
HTTP/1.1 201 Created
Content-Type: text/html; charset=utf-8
Date: Wed, 17 Aug 2022 15:19:56 GMT
Server: waitress
X-Call-Id: 4121651e-8bd4-470a-8ad3-70ecd68b8194
X-Duration-Seconds: 0.387640
X-Start-Time: 1660749596315319961
Content-Length: 69
{"batch_id": "0edb0a1f-5be5-4e94-9fd7-23ee6e823e1e", "batch_size": 1000}%
I ran these batches in a k3d cluster on my local machine and configured the queue-worker to run a maximum of ten parallel invocations. Processing this batch took around 3m20s.
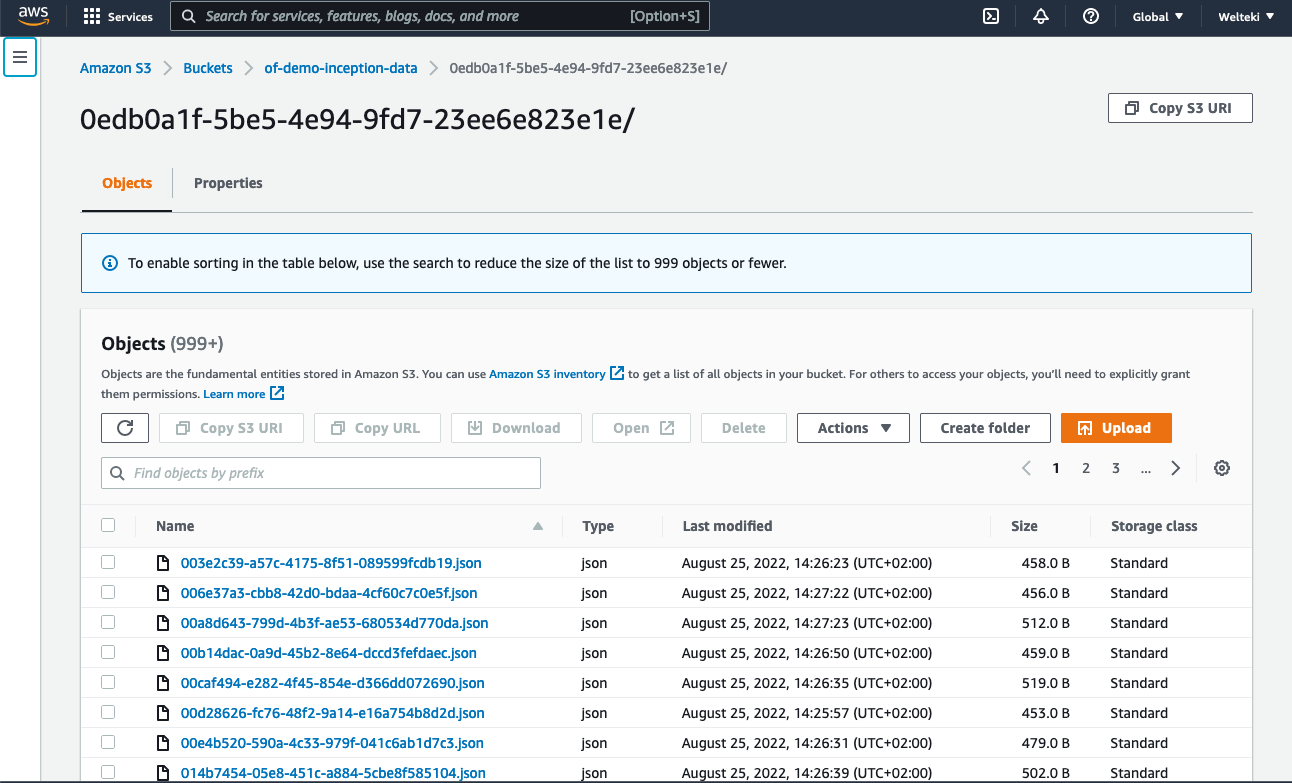
The S3 console shows a batch folder with all the results and the output summary.
A sample of the output.json:
{
"batchId": "0edb0a1f-5be5-4e94-9fd7-23ee6e823e1e",
"batchStarted": "1661430334.4237344",
"batchCompleted": "1661430507.6409442",
"failed": {
"count": 26,
"results": [
{
"url": "https://upload.wikimedia.org/wikipedia/commons/5/52/Japan_Guam_Landing_1941.gif",
"statusCode": 400,
"result": "bad image mime type image/gif"
},
....
]
},
"passed": {
"count": 974,
"results": [
{
"url": "https://upload.wikimedia.org/wikipedia/commons/b/b0/1923._Esen_duncan.jpg",
"statusCode": 200,
"result": [
{
"name": "suit",
"score": "0.30214"
},
{
"name": "bow_tie",
"score": "0.12600212"
},
{
"name": "lab_coat",
"score": "0.10206755"
},
{
"name": "Windsor_tie",
"score": "0.07296498"
},
{
"name": "microphone",
"score": "0.04056441"
}
]
},
....
],
}
OpenFaaS emits a number of metrics to help optimise these kinds of workflows and track down issues. We have a number of Grafana dashboards available to visualise these metrics.
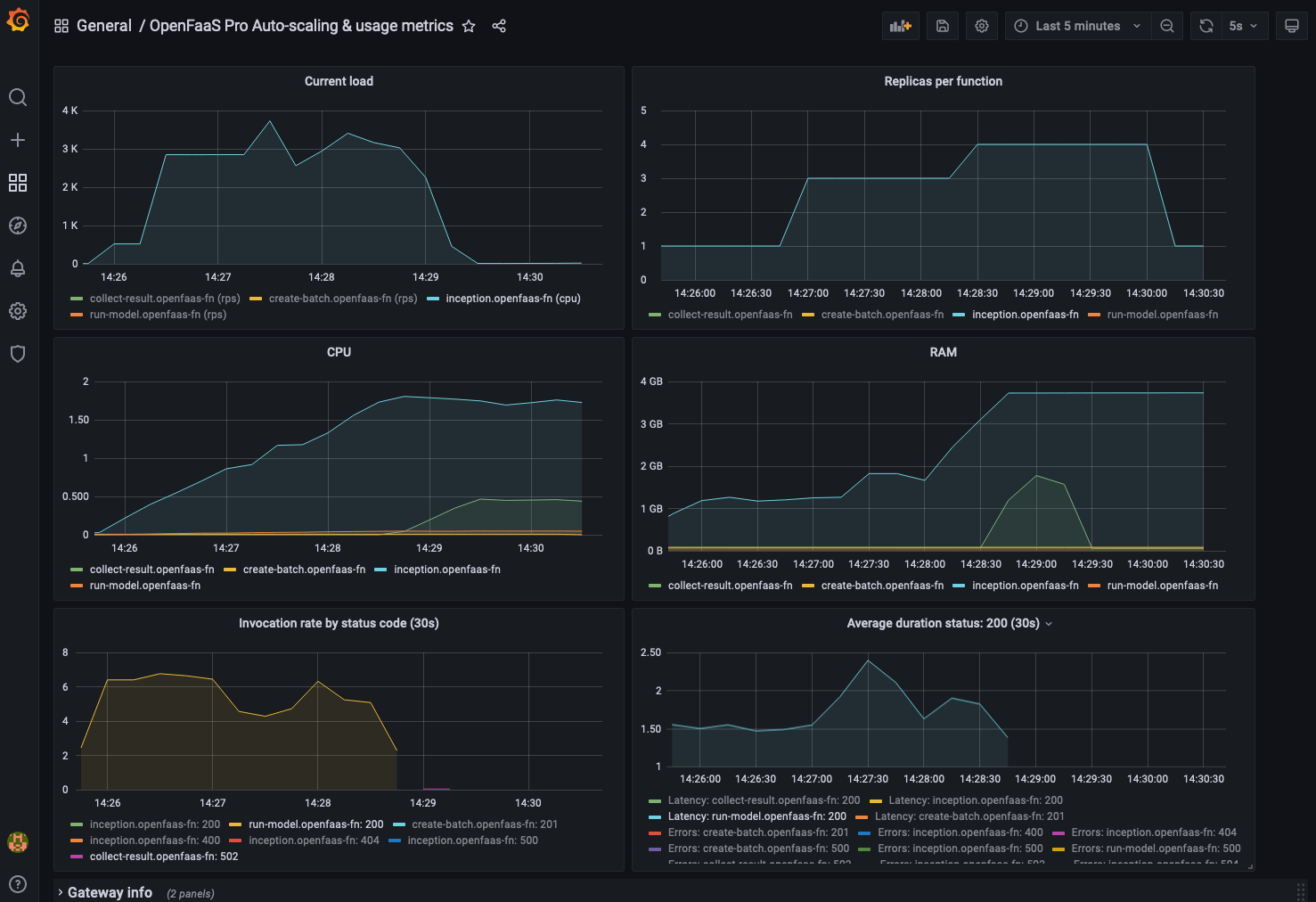
Grafana dashboard showing the inception function being scaled up while processing a batch of a 1000 URLs.
These metrics helped me diagnose some unexpected behaviour during the initial testing of this workflow. The cpu scaling target for the inception function was set to low. Because this function is cpu intensive and the machine learning model is downloaded when the function is started, the scaling target would be exceeded and the autoscaler would scale up the function. This caused a feedback loop resulting in the the function being scaled up and down without there being any actual invocations.
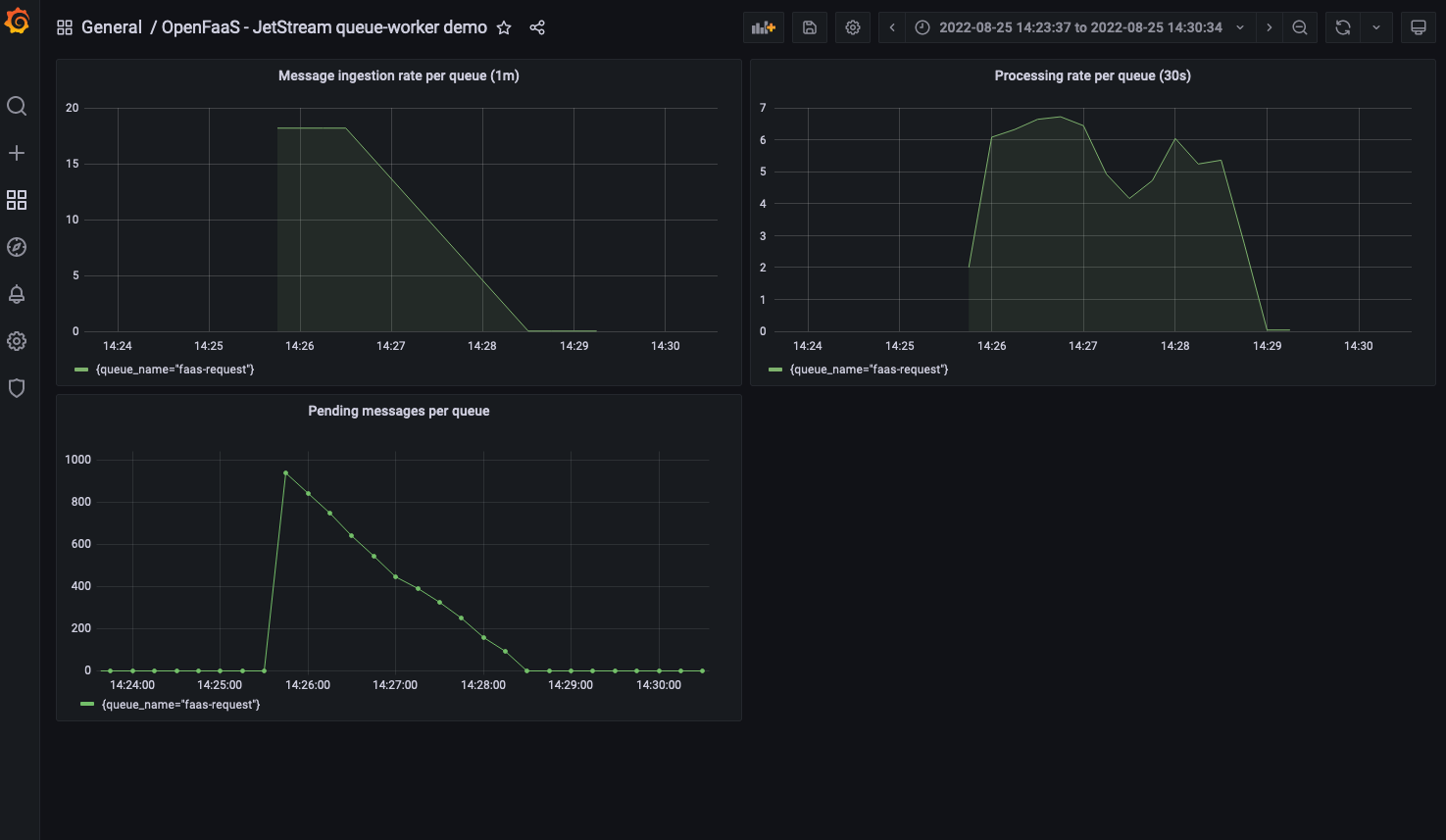
Grafana dashboard showing the queue-worker burn through the 1000 messages created by the
create-batchfunction.
Conclusion
We set out to show how the MapReduce pattern could be implemented with OpenFaaS, first by fanning out requests, using the built-in asynchronous system and queue-worker, then by fanning back in again by using some form of shared storage.
We created this example as a starting point, so that you can try it out in a short period of time, then adapt it to your own functions or machine learning models. OpenFaaS doesn’t have any one component called a “workflow engine”, but what we’ve shown you here and in a previous post Back pressure, is that you can orchestrate functions in a powerful way.
Further work
The example was written using python because it is often used for data science and machine learning projects, but this pattern can be implemented in other languages too. You can find tutorials for Node.js, Ruby, C# Java and Go here: OpenFaaS samples
Functions are a natural fit for processing data. As we see more people use MapReduce with OpenFaaS we may consider building a generic component to help implement this pattern. Would you find that useful?
If you’d like to talk to us about anything we covered in this blog post: feel free to reach out
We also run a Weekly Office Hours call that you’re welcome to join.

Han Verstraete
Associate Software Developer, OpenFaaS Ltd

Alex Ellis
Founder of @openfaas.
