Learn how and why to use a custom health or readiness endpoint for Kubernetes workloads and OpenFaaS Functions too.
OpenFaaS Pro has had HTTP health check or (liveness) probe support for some time, but recently we’ve worked with customers to bring custom HTTP readiness support for functions too.
In this article, I’ll explain what the difference is between the two, and what distinct job they perform for Kubernetes workloads. We’ll then see a few demos where you can participate too.
Kevin Lindsay from Surge helped co-design this feature with our team, and here’s what he had to say:
“We apply hard concurrency limits to our OpenFaaS Pro functions and had already been using the custom health checks. The new custom readiness support has resulted in higher throughput with fewer retries for both synchronous and asynchronous messages. Ultimately, it made our end-user experience much more responsive.” - Kevin Lindsay, Surge
To use the features described in this blog post you need at least version 0.9.9 of the of-watchdog. Make sure your functions are using the latest version of our templates or update the of-watchdog version in your custom templates.
Introduction
OpenFaaS is a platform that provides a serverless FaaS experience on any cloud or private datacenter.
There are alternatives to using OpenFaaS, like writing your own Kubernetes micro-services, for OpenFaaS itself, we built a set of Kubernetes Deployments and Services.
This can be rather overwhelming when you start out with Kubernetes, and even when you’re a seasoned professional, you will end up programming by copy and paste, not because you couldn’t write it all over from scratch, but because it’s tedious and slow.
With OpenFaaS, we try to abstract away a lot of the YAML and options you would need to know about and chose when working with Kubernetes directly.
Health (also called liveness) and readiness are two concepts that apply to Pods in Kubernetes, they’re often a source of confusion too.
- If a health check fails, the Pod should be killed and restarted.
- If a readiness check fails, it should have its endpoints removed from circulation, so that it receives no more traffic.
So what’s the difference?
One means the program will definitely exit, and the other means the program is healthy and shouldn’t exit, but at least for a time shouldn’t receive any more traffic.
These probes can be either HTTP calls, TCP connections or executions of processes within a container image. OpenFaaS only uses HTTP probes.
Kubernetes docs: Configure Liveness, Readiness and Startup Probes
Why would a function fail a health check?
Let’s say a HTTP server binds port 8080, and for some reason that server process crashed.
Why would a function be not ready?
You may be downloading data from S3 into a temporary directory, such as a video, processing it and then freeing up that space again.
A readiness check may start failing when the temporary directory is 70% full, so that the Pod doesn’t crash.
Likewise, if you’re using a managed database like the one offered by DigitalOcean and can only open 20 database connections, you may have your function fail its readiness check when it reaches 20 open connections.
Another example would be that you’re running inference against a Machine Learning (ML) model, and you know it’s flakey, but you don’t have time to fix it. So instead, you limit to only processing 100 requests, at the time you get to 100, you start failing the readiness check so that the traffic can get directed away to other Pods.
If you had 5 replicas of the ML serving function, and 4 failed their readiness check, then Kubernetes would remove their IP addresses from the available pool, meaning all subsequent requests would go to the free Pod.
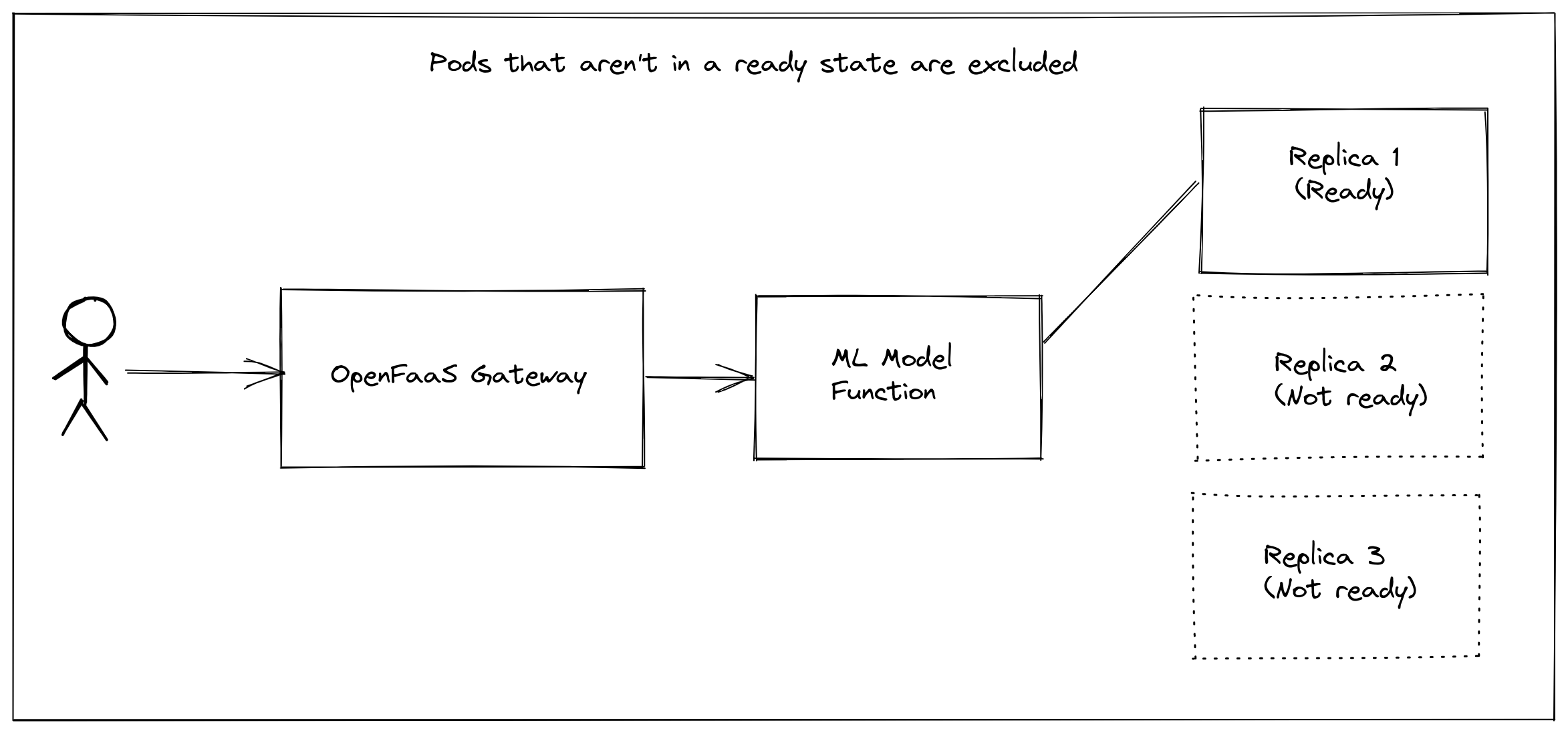
Readiness in action, removing Kubernetes endpoint IP addresses from the available set.
A demo without readiness
Deploy the sleep function with a hard limit of 1 inflight request:
faas-cli store deploy sleep \
--env max_inflight=1 \
--label com.openfaas.scale.min=1 \
--label com.openfaas.scale.target=1 \
--label com.openfaas.scale.max=10 \
--label com.openfaas.scale.type=capacity
See it deployed:
kubectl get deploy -n openfaas-fn
NAME READY UP-TO-DATE AVAILABLE AGE
sleep 1/1 1 1 26h
Now invoke it with 21 concurrent requests using hey:
hey -c 20 -z 60s -H "X-Sleep-Duration: 2s" http://127.0.0.1:8080/function/sleep
You’ll see the function scale up to 10/10 replicas.
kubectl get deploy -n openfaas-fn sleep -w
NAME READY UP-TO-DATE AVAILABLE AGE
sleep 1/10 10 1 23s
sleep 2/10 10 2 24s
sleep 3/10 10 3 24s
sleep 4/10 10 4 24s
sleep 5/10 10 5 26s
sleep 6/10 10 6 26s
sleep 7/10 10 7 26s
sleep 8/10 10 8 26s
sleep 9/10 10 9 26s
sleep 10/10 10 10 28s
Hey will show a number of 429 status codes, but the “Available replicas” field is 10, even when we know all the functions are overloaded.
The side-effect is that traffic may go to Pods which are overloaded, instead of Pods that are ready.
How to apply readiness for concurrency limits
Concurrency limits are not the only kind of readiness check available, you can also provide your own (we’ll get to that soon).
Redeploy the function with a custom readiness path:
faas-cli store deploy sleep \
--env max_inflight=1 \
--label com.openfaas.scale.min=1 \
--label com.openfaas.scale.target=1 \
--label com.openfaas.scale.max=10 \
--label com.openfaas.scale.type=capacity \
--annotation com.openfaas.ready.http.path="/_/ready" \
--annotation com.openfaas.ready.http.initialDelaySeconds=1 \
--annotation com.openfaas.ready.http.periodSeconds=1
Now we have:
kubectl get deploy -n openfaas-fn sleep
NAME READY UP-TO-DATE AVAILABLE AGE
sleep 1/1 1 1 5m21s
kubectl get endpoints/sleep -n openfaas-fn -o wide
NAME ENDPOINTS AGE
sleep 10.42.0.16:8080 5m36s
This time, when you run hey, notice how the “Available” number changes, along with the available endpoints IP addresses for the functions
hey -c 20 -z 120s -H "X-Sleep-Duration: 5s" http://127.0.0.1:8080/function/sleep
Output:
kubectl get deploy -n openfaas-fn sleep -w
NAME READY UP-TO-DATE AVAILABLE AGE
sleep 1/1 1 1 8m41s
sleep 1/10 1 1 9m21s
sleep 1/10 1 1 9m21s
sleep 1/10 1 1 9m21s
sleep 1/10 6 1 9m21s
sleep 2/10 6 2 9m24s
sleep 3/10 6 3 9m24s
sleep 4/10 6 4 9m24s
sleep 5/10 6 5 9m24s
kubectl get endpoints/sleep -n openfaas-fn -w
NAME ENDPOINTS AGE
sleep 10.42.0.16:8080,10.42.1.21:8080,10.42.2.18:8080 + 2 more... 10m
Notice how there are 5 Pods ready, but 6 of them are fully deployed in the cluster? there’s also only 6 available endpoints, despite there being 10 Pods.
Why?
Kubernetes is routing traffic away from the busy Pods which have a hard limit for concurrency.
It’ll do the same if you have a custom health endpoint for the usecases like: disk space, available RAM, open database connections or some other issue with a downstream API.
Configuration options for functions
There are some default values set for all functions, configured in the Helm chart, you’ll see us talk about these at the end of the post.
These annotations are supported for the readiness check:
com.openfaas.health.http.path- the path to check for readinesscom.openfaas.ready.http.periodSeconds- how often to check the readiness endpoint?com.openfaas.ready.http.initialDelaySeconds- how long to wait before checking the readiness endpoint of a newly deployed or updated function?com.openfaas.ready.http.timeoutSeconds- number of seconds after which the probe times out.com.openfaas.ready.http.successThreshold- how many consecutive successes should there be for the probe before the function is considered ready?com.openfaas.ready.http.failureThreshold- how many times should a readiness probe fail until the function is considered not ready?
And the following annotations are supported for the health check (liveness probe):
com.openfaas.health.http.path- the path to check for livenesscom.openfaas.health.http.periodSeconds- how often to check the health endpoint?com.openfaas.health.http.initialDelaySeconds- how long to wait before checking the health endpoint of a newly deployed or updated function?com.openfaas.health.http.timeoutSeconds- number of seconds after which the probe times out.com.openfaas.health.http.failureThreshold- how many times should a liveness probe fail until the function is considered unhealthy?
Learn more about these options: Docs: OpenFaaS workloads
Your own readiness endpoint
Let’s say that you’re writing a program in Python, we’d recommend the python3-http template for that.
faas-cli template store pull python3-http
OPENFAAS_PREFIX=alexellis2 faas-cli new --lang python3-http readyornot
Then you can write code in readyornot/handler.py to decide whether the function is handling a normal request or a readiness check:
counter = 0
def handle(event, context):
global counter
if event.path == "/custom-readiness":
counter = counter + 1
ready_code=200
if counter > 20:
ready_code = 500
return {
"statusCode": ready_code,
"body": "ready response"
}
if event.path == "/reset":
counter = 0
# The normal flow of your application goes here:
return {
"statusCode": 200,
"body": "Hello from OpenFaaS!"
}
Then edit your stack.yaml to apply the required annotation:
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
readyornot:
lang: python3-http
handler: ./readyornot
image: alexellis2/readyornot:latest
annotations:
com.openfaas.ready.http.path: /custom-readiness
com.openfaas.ready.http.initialDelaySeconds: 2
com.openfaas.ready.http.periodSeconds: 2
Deploy the function and watch it passing readiness, then failing after the internal counter gets to 20:
faas-cli up -f readyornot.yml
kubectl get deploy/readyornot -n openfaas-fn -w
NAME READY UP-TO-DATE AVAILABLE AGE
readyornot 1/1 1 1 7s
readyornot 0/1 1 0 47s
Kubernetes will keep on calling the ready endpoint until the function can serve traffic again.
If you want your function to actively be killed and restarted, that’s where a health endpoint comes in (explained later).
Combine custom readiness with your own handler
You may want to combine a hard concurrency limit with your own readiness handler.
Let’s say your Python function can take 2 requests maximum, before it needs to start rejecting requests, and at the same time, it can also go to an unready state if some other condition happens.
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
readyornot:
lang: python3-http
handler: ./readyornot
image: alexellis2/readyornot:latest
environment:
max_inflight: 2
ready_path: /custom-ready
annotations:
com.openfaas.ready.http.path: /_/ready
com.openfaas.ready.http.initialDelaySeconds: 2
com.openfaas.ready.http.periodSeconds: 2
Concurrency limiting is handled in the OpenFaaS Watchdog component, so needs an environment variable:
environment:
max_inflight: 2
We then need to tell the OpenFaaS watchdog that it should run its max_inflight check along with another separate one belonging to the function.
Instead of using our custom path directly, we use the watchdog’s internal API path: /_/ready
com.openfaas.ready.http.path: /_/ready
Then, we need to set an environment variable for the watchdog to ensure it also calls the function’s readiness endpoint, and the combination of both will be used to pass or fail the check:
environment:
ready_path: /custom-ready
Now, whenever Kubernetes checks one of your function Pods, it’ll first call /_/ready, which is handled by the OpenFaaS watchdog.
The watchdog will look to see if you’ve set a ready_path, if you haven’t it’ll return healthy, if max_inflight is both set and not exceeded. If you have provided ready_path, as in our example, then the watchdog will invoke that endpoint in your function, and return a local OR operation on both.
So if max_flight is good, and the custom check are good, the check will pass. If max_inflight is exceeded, it fails. If max_inflight is good, but the custom check fails, the check fails.
What about custom health endpoints?
Now that we’ve added readiness to OpenFaaS, we have heard from customers that told us they no longer need a custom health endpoint.
But if you want to try it anyway, you can combine them both, because remember, they serve two distinct purposes.
annotations:
com.openfaas.health.http.path: "/custom-health"
com.openfaas.health.http.initialDelaySeconds: 10
com.openfaas.health.http.periodSeconds: 5
What about my slow starting functions?
If you have a function that generally is slow to start, but then once it’s ready, will stay that way, then you can fine-tune the checks and experiment to get them right for your use-case.
You may need this if you load data from a cache, download large files or load an ML model in memory before accepting requests.
What if your model is really very large and takes 60 seconds to load?
annotations:
com.openfaas.ready.http.path: "/custom-ready"
com.openfaas.ready.http.initialDelaySeconds: 60
com.openfaas.ready.http.periodSeconds: 5
Here, we do the first check after 60 seconds, then every other check is on a 5 second timer.
Scale from zero
When scaling from zero the gateway uses the kubernetes replica count for a function to determine if the function is available before it forwards any traffic.
If you are using a service mesh like Istio or Linkerd we recommend enabling function probing. With function probing enabled the gateway additionally checks the functions readiness endpoint. Probing can be enabled in the OpenFaaS Chart by setting gateway.probeFunctions to true.
However if you run into any failed invocations whilst scaling from zero, even when you are not running a service mesh, we would recommend turning on function probing.
Do I always need to set an initial delay and period seconds value?
If you don’t set the initialDelaySeconds or periodSeconds values, then OpenFaaS will default to using the default values set in the OpenFaaS Helm chart, or the defaults of Kubernetes.
You’ll also notice that we expose timeoutSeconds at the chart level, some of our customers use this with functions that are slow to respond to their readiness and liveness checks. Making this number higher gives the function longer to respond.
functions.readinessProbe.initialDelaySeconds
functions.readinessProbe.periodSeconds
functions.readinessProbe.timeoutSeconds
functions.livenessProbe.initialDelaySeconds
functions.livenessProbe.periodSeconds
functions.livenessProbe.timeoutSeconds
See also: OpenFaaS Helm chart
Wrapping up
I wanted to give you a quick overview of the differences between readiness and health, or as it’s also called “liveness” and how that applies to OpenFaaS using Kubernetes.
If you have questions, please check out the Workloads page in the docs, or feel free to get in touch
You may also like seeing readiness applied to functions in case-studies:
- How to process your data the resilient way with back pressure
- Generate PDFs at scale on Kubernetes using OpenFaaS and Puppeteer
See also: OpenFaaS Watchdog
Alex

Alex Ellis
Founder of @openfaas.
