Learn how we collaborated with our customers to rethink and rebuild the OpenFaaS autoscaler for functions.
In this article we’ll compare and contrast the three new autoscaling strategies with the original approach the Community Edition (CE) took in 2017.
If you’d like a detailed overview of the changes, and how they compare, Alex spoke about this at Prometheus Day at KubeCon EU 2022:

Watch now: How and Why We Rebuilt Auto-scaling in OpenFaaS with Prometheus
At the end of this article, you’ll find a list of tutorials and case-studies that we built in collaboration with our customers around concurrency limiting functions, fanning in and out requests, long running functions and data processing pipelines.
Introduction
Without an autoscaler, it’s up to the operator or developer to set a static amount for how many copies of each function should run in a cluster. This is a kind of capacity planning, and most of the time, because traffic can be variable, it could be inefficient. Too few replicas and users may face errors or degraded performance, too many, and the cluster may be underutilised and inefficient.
So the original autoscaler for OpenFaaS was built to scale functions horizontally with the aim to match the demand observed through metrics. The original experience was simple, integrated and had a good developer experience - set the min and max levels, and then forget about it.
It used a Request Per Second (RPS) strategy and started adding replicas in a linear way whenever a single threshold was met for a function and traffic remained above that point. Even though this mode sounds simple, Alex says in his KubeCon talk that users found it useful in production.
The new autoscaling modes work in a very similar way to the old one in CE, using labels applied to the function:
functions:
sleep:
skip_build: true
image: ghcr.io/openfaas/sleep:latest
labels:
com.openfaas.scale.min: 1
com.openfaas.scale.max: 10
com.openfaas.scale.target: 5
com.openfaas.scale.type: capacity
The old mechanism relied on AlertManager to trigger webhooks when certain traffic patterns were observed, which the gateway then used to scale a function proportionally, every time the alert fired. That also meant that if the RPS was at the threshold, of let’s say 100 RPS, the function would keep on scaling up until it reached the maximum, even if the RPS value was still 100.
This legacy scaling is still available and used for the OpenFaaS Community Edition. It is a good way to kick the tires with scaling OpenFaaS functions but it’s capabilities might fall short for certain types of functions:
- Different functions might need to be scaled at different target loads. This is not possible because there is only one rule for all functions.
- Scaling long running functions does not work. You may be starting 15 invocations per second but when the function takes 20s or more to complete there simply is not enough data available to trigger an alert.
- Not all functions can be scaled based on Request Per Second (RPS). Some functions are CPU-bound or they are limited by other factors such as database connections.
At the beginning of 2022 we released a new autoscaler for OpenFaaS Pro customers. This autoscaler was designed with our customers to fix both the original limitations of the CE approach, and to suit the way they used their functions (data processing, ML model inference, concurrency-limited functions, etc).
We created three modes, each of which can be fine-tuned for each function, and instead of adding replicas in a linear way, it calculates the number of replicas based upon the current load of the system.
The new modes:
-
Capacity
In capacity mode functions are scaled based upon inflight requests (or connections). It is ideal for long running functions, this means functions that take seconds or even minutes to complete.
Functions which can only handle a limited number of requests at once, like video encoding functions or web scraping functions using a headless browser, can also be scaled efficiently with capacity mode.
-
Request Per Second (RPS)
RPS mode is based upon requests per second completed by the function. A good fit for functions which execute quickly and have high throughput.
It’s the most similar to the original scaling in CE, but can be tuned per function and doesn’t add superfluous replicas when the RPS is at the threshold.
-
CPU
In this mode scaling happens based upon CPU usage of the function. This strategy is ideal for CPU-bound workloads, or where Capacity and RPS are not giving the optimal scaling profile.
Additionally functions can be scaled to zero when they are idle. Scaling to zero is an opt-in feature on a per function basis. It can be used in combination with any of the three scaling modes listed above for increased efficiency.
There is a trade-off when using Scale to Zero, learn more about it here: Dude, where’s my coldstart?
What about Kubernetes’ own auto-scaler?
OpenFaaS functions can also be scaled using Kubernetes’ Horizontal Pod Autoscaler (HPA). However, we got feedback from customers that it was not reactive enough for functions, having been designed for generic workloads. It also means creating and maintaining a separate YAML definition for every function, which is not ideal for the developer experience.
With the new autoscaler we kept the same developer experience offered by OpenFaaS, but rethought the various ways you can scale a function.
How you scale long running functions
When we were developing the new autoscaler, Kevin Lindsay at Surge (an OpenFaaS Pro customer) told us he was using the sleep function from the function store to test autoscaling. Why? It’s a good proxy to simulate a long running function like processing a large amount of records in a data processing pipeline or encoding a video.
In this example we’ve configured the function to block for 20 seconds.
functions:
sleep:
skip_build: true
image: ghcr.io/openfaas/sleep:latest
labels:
com.openfaas.scale.min: 1
com.openfaas.scale.max: 10
com.openfaas.scale.target: 5
com.openfaas.scale.target-proportion: 0.9
com.openfaas.scale.type: capacity
environment:
write_timeout: 25s
exec_timeout: 25s
sleep_duration: 20s
To be on the safe side, we’ve also set a write_timeout and exec_timeout as per the Extended timeout guide.
We can configure autoscaling for the function via labels:
com.openfaas.scale.min- The minimum number of replicas to scale to.com.openfaas.scale.max- The maximum number of replicas to scale to.com.openfaas.scale.target- Target load per replica for scaling.com.openfaas.scale.target-proportion- Proportion as a float of the target i.e. 1.0 = 100% of target.com.openfaas.scale.type- Scaling mode.
All available configuration labels and there default values can be found in the autoscaling documentation
The function is running in capacity mode and the target load is 5 inflight requests (or 5 connections). The target proportion is set to 0.9.
This means the autoscaler will try to maintain an average load of 90% of the target load per function by scaling the function up or down. The scaler will only scale between the configured minimum and maximum number of replicas, in this case 1 and 10.
It does this by running a query periodically to calculate the current load. The current load is used to calculate the new number of replicas:
desired = ready pods * ( mean load per pod / ( target load per pod * target-proportion ) )
For example:
- The load on the sleep function is measured as 15 inflight requests.
- There is only one replica of the sleep function.
mean per pod = 15 / 1
4 = ceil ( 1 * ( 15 / ( 5 * 0.9 ) )
Therefore the function will be scaled to 4 replicas.
We’re using K6.io to simulate a load on the function. In this example we gradually ramp up the amount of invocation from 0 to 70 over a 4 minute period. The Grafana dashboard that we provide can be used to inspect the function and see how it performed under this load.
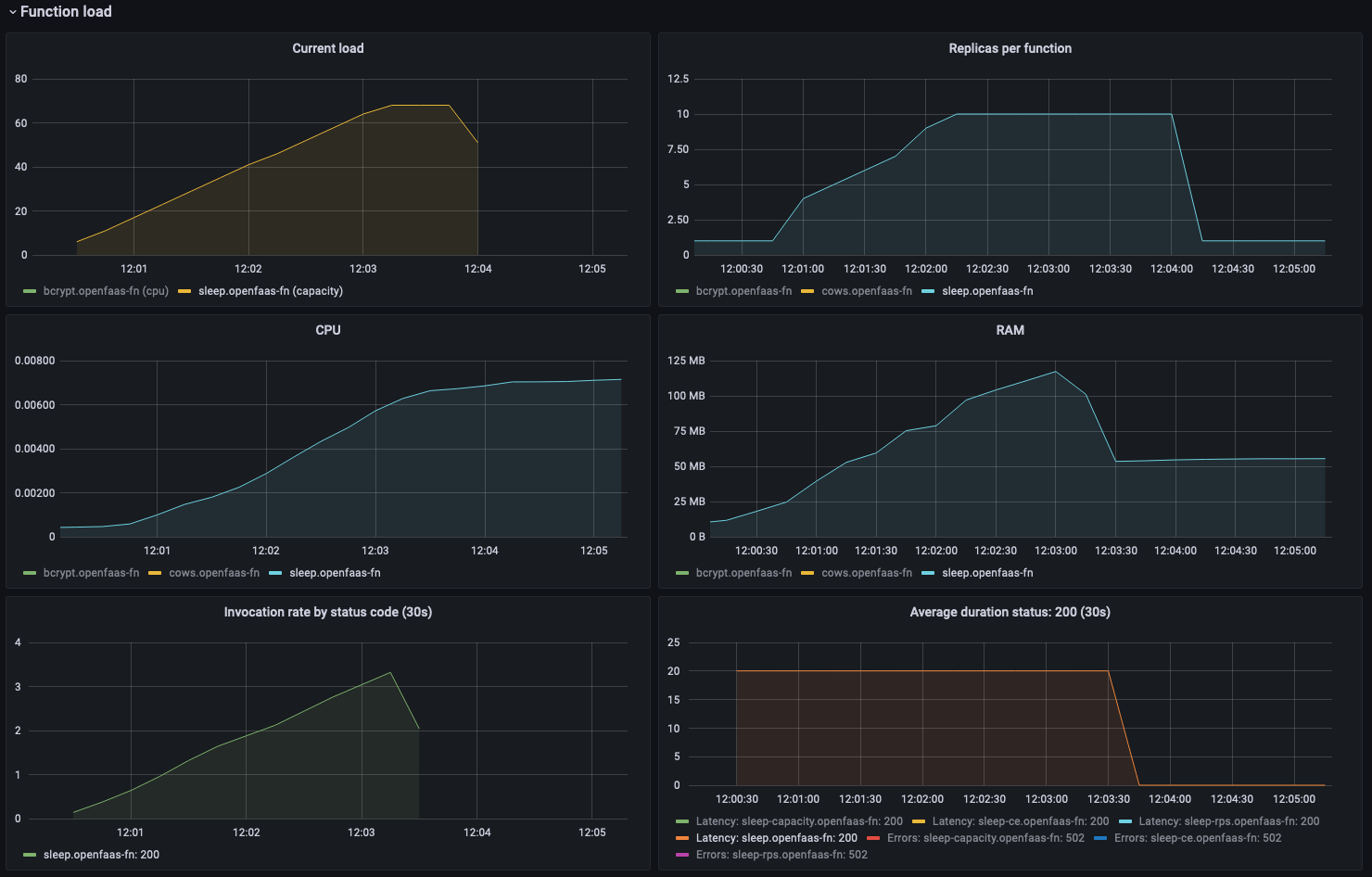
Grafana dashboard showing more replicas of the sleep functions are added as the amount of concurrent requests gradually increases.
The K6 script to generate this load is available on GitHub
The first graph on the top left shows the load on the function. This load is used for the scaling calculations. As you can see the load gradually increased from 0 to 70 inflight requests over the course of our load test.
The graph on the top right shows the number of replicas for our function. It clearly shows our function was gradually scaled up to the configured maximum amount of replicas as the load increased.
The next two graphs show the CPU and RAM usage of the function. We can see that the CPU rises as we increase the load on the function. Still it only peaks at 70mi which tells us this is quite an efficient function. The RAM usages increase as replicas of our function are added. This is an aggregated view, it shows the total amount of RAM used by the function. To get an idea of the amount of memory used by each replica you should divide it by the replica count.
The bottom two graphs show the invocation rate and the average invocation duration. Looking at the graph for the invocation duration we can see that each invocation takes 20 seconds to complete. This is what we would expect as the function was configured to sleep for 20 seconds.
What if you need to limit concurrency per replica?
Some functions, like certain ML models, video encoding functions or web scraping functions, may only be able to handle a limited amount of connections at once.To handle these kinds of workloads OpenFaaS supports setting a hard concurrency limit on functions. Any requests exceeding the limit are dropped with a 429 error.
This feature can play together nicely with the autoscaler, we can configure it to scale up functions and increase capacity as this limit is reached. We’re going to show you how to limit to one request per replica, but the value can be tuned to whatever number makes sense, whether that’s 1, 100, or 1000+.
We will use an example from a case-study we did in one of our previous blog posts: Generate PDFs at scale on Kubernetes using OpenFaaS and Puppeteer.
For the case study we created a function that uses Puppeteer to generate PDFs from web pages. Each replica of the PDF generation function can only run so many browsers or browser tabs at once so we set a hard concurrency limit on it.
We want to automatically scale up the function so that we can handle more requests even if the concurrency limit for the function is reached. The capacity based autoscaling can be used for this.
The functions stack.yaml definition looks like this:
functions:
page-to-pdf:
lang: puppeteer-nodelts
handler: ./page-to-pdf
image: welteki2/page-to-pdf:latest
environment:
max_inflight: 1
labels:
com.openfaas.scale.min: 1
com.openfaas.scale.max: 5
com.openfaas.scale.target: 1
com.openfaas.scale.type: capacity
com.openfaas.scale.target-proportion: 0.7
annotations:
com.openfaas.ready.http.path: /_/ready
A hard limit is set for the function of 1 concurrent request using the max_inflight environment variable. Any subsequent requests would be dropped and receive a 429 response.
environment:
max_inflight: 1
We then need to configure OpenFaaS to scale up the function so that we can handle more than one request at a time:
labels:
com.openfaas.scale.min: 1
com.openfaas.scale.max: 5
com.openfaas.scale.target: 1
com.openfaas.scale.type: capacity
com.openfaas.scale.target-proportion: 0.7
We use a scale target of 1 and set the target proportion to 0.7 to ensure the function is immediately scaled up once there is a request inflight.
Note that we also set an annotation com.openfaas.ready.http.path to configure a custom readiness path for the function:
annotations:
com.openfaas.ready.http.path: /_/ready
By configuring the readiness check we make sure the endpoints for functions that have reached their concurrency limit are marked as unavailable. This way Kubernetes routes away traffic from pods that are overload.
Learn more about readiness checks and how they can be used to optimise function throughput with fewer retries in this post: Custom health and readiness checks for your OpenFaaS Functions
The graph for the invocation rate shows how there initially are a lot of 429 responses but as more replicas of the pdf generation functions are added the number of 429 responses drops.
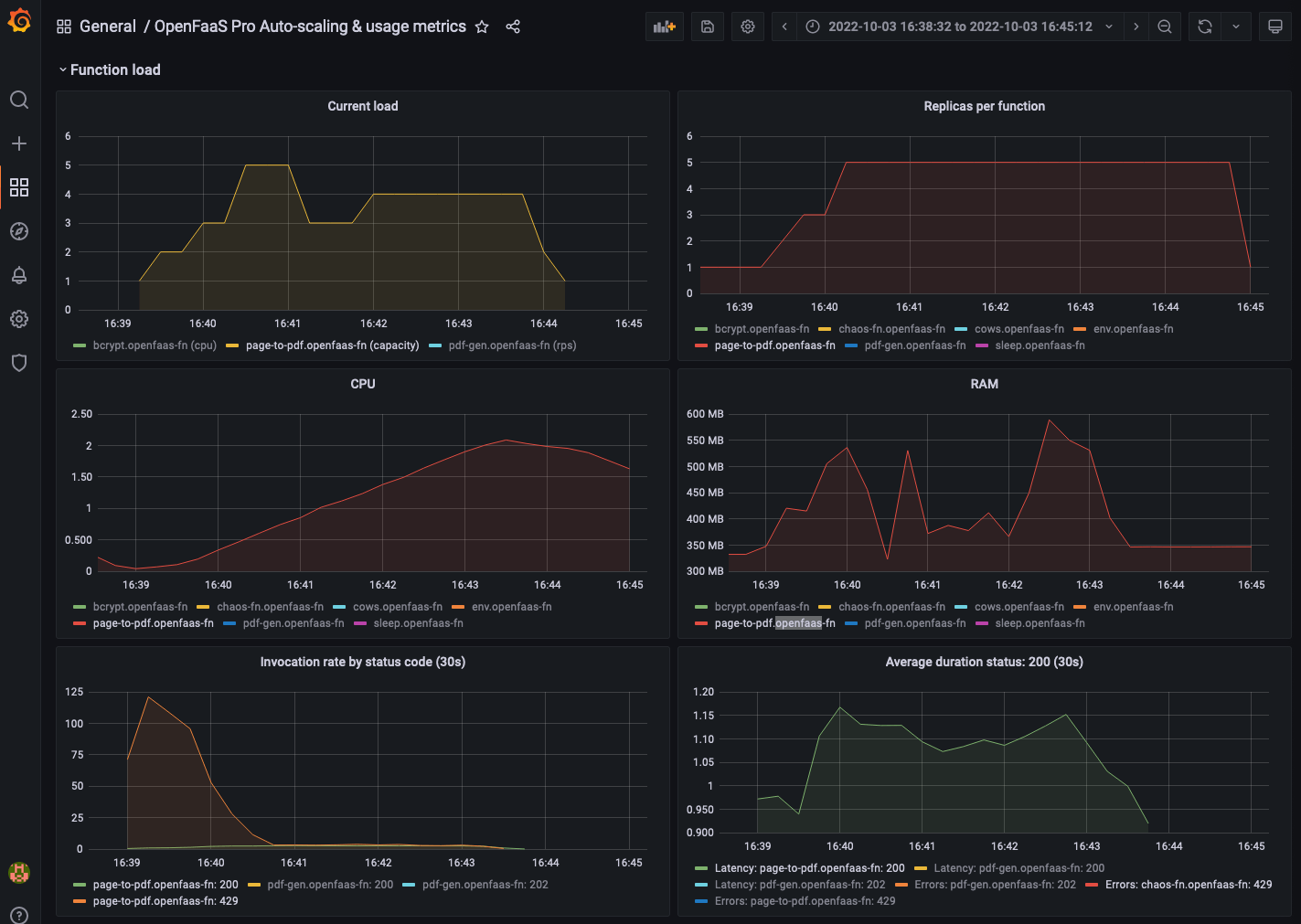
Grafana dashboard showing the replicas and invocation rate for the
page-to-pdffunction.
What about CPU based scaling?
Some workloads are CPU-bound or can not be scaled well using the rps or capacity mode. This might be the case for certain ML models or encryption and hashing functions like the bcrypt function that we will be using in this example. Bcrypt is a password hashing function that is used in many different systems.
For this example we deployed the bcrypt function with this configuration:
functions:
bcrypt:
skip_build: true
image: alexellis2/bcrypt:0.1.2
labels:
com.openfaas.scale.min: 1
com.openfaas.scale.max: 10
com.openfaas.scale.target: 500
com.openfaas.scale.type: cpu
The scaling target is configured in milli-CPU, so 1000 accounts for 1 CPU core. For this example we set the scaling target to 500mi. This means the autoscaler will try to ensure the average CPU load per replica stays around half a cpu core by adding or removing replicas of the function.
We run a similar load test as in the previous examples. Over a period of 4 minutes the load is gradually ramped up from 0 to 120 requests per second.
You can find the test script we used on GitHub.
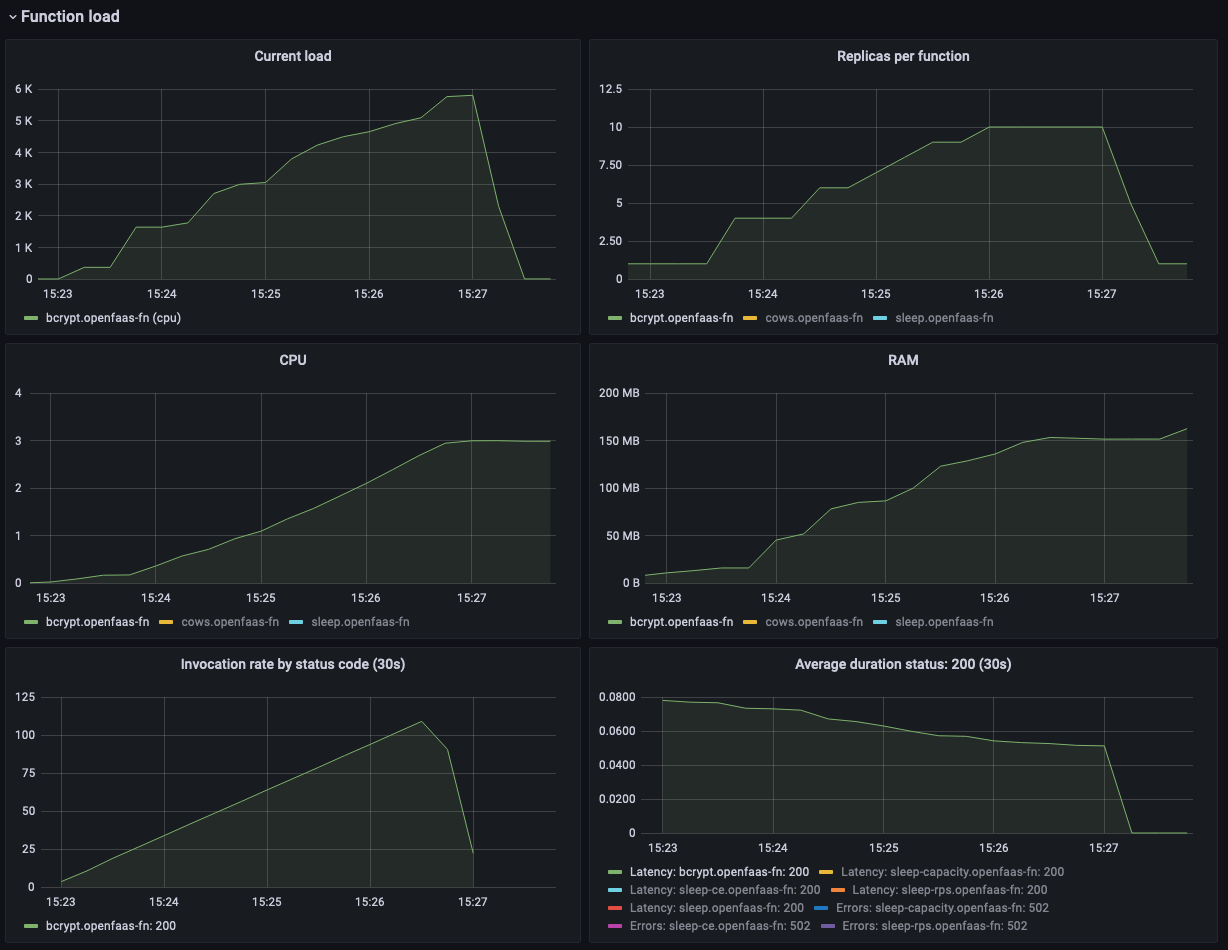
Grafana dashboard showing more replicas of the bycrypt function are added as the CPU load gradually increases.
A comparison to the Community Edition (CE)
To compare the scaling behaviour of the OpenFaaS Pro scaler with the Community Edition (CE) scaler we deployed the sleep function on a CE cluster with a similar configuration as in our first example. We than ran the same K6 load test against it. Invocations where gradually ramped up from 0 to 70 concurrent invocations over a 4 minute period.
functions:
sleep-ce:
skip_build: true
image: ghcr.io/openfaas/sleep:latest
labels:
com.openfaas.scale.min: 1
com.openfaas.scale.max: 10
com.openfaas.scale.target: 10
environment:
write_timeout: 30s
exec_timeout: 30s
sleep_duration: 20s
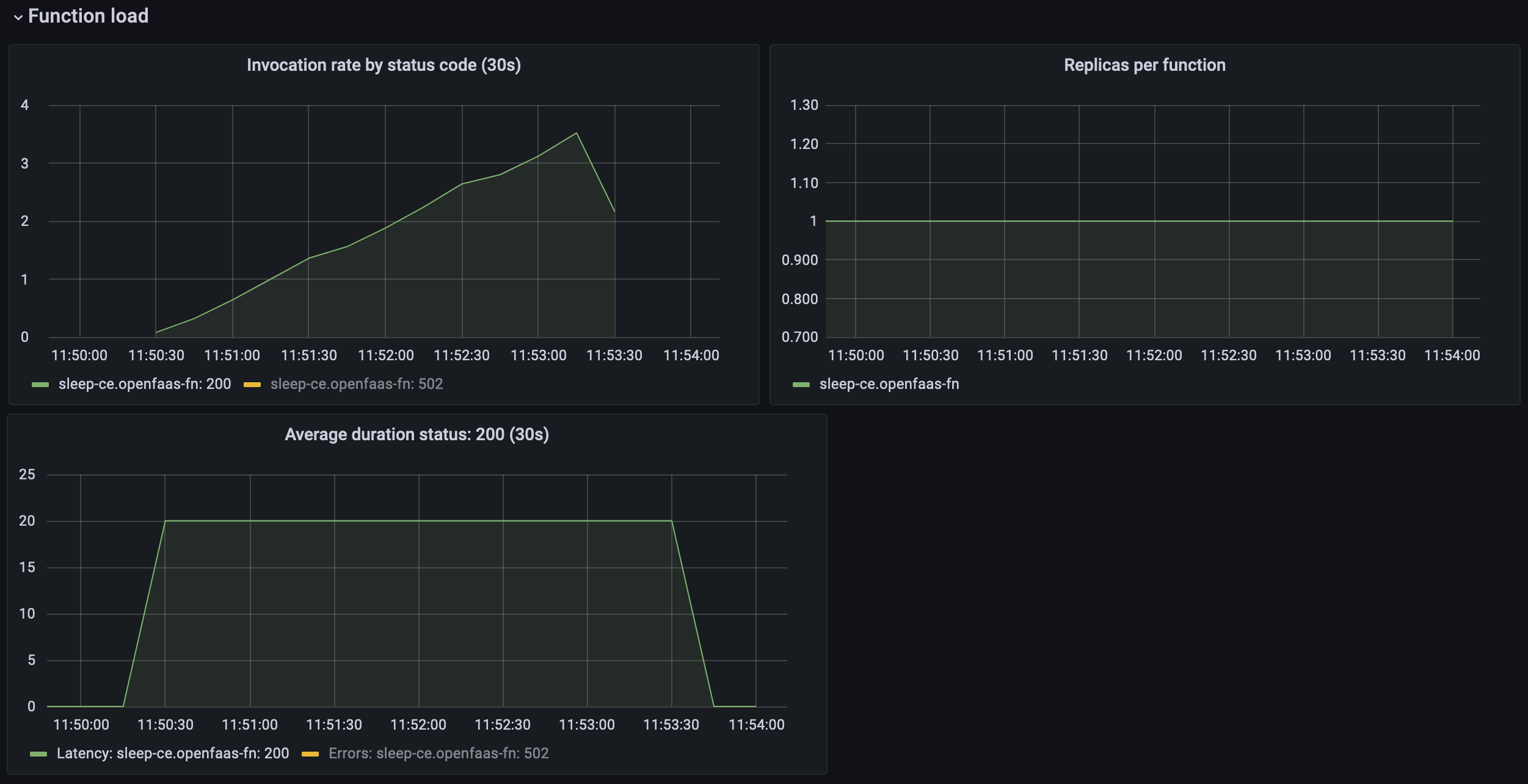
Grafana dashboard showing how the CE scaling fails to scale the function.
The first thing you might notice here is that the Community Edition has less metrics available. We get no RAM and CPU metrics and we can not inspect the load used for the autoscaling calculation.
The second thing that may catch your eye is the fact that our function was never scaled up even if we ran the same load against it. We gradually ramped up the load to 70 concurrent invocations over a period of 4 minutes. Because the function takes a long time to complete there is not enough data to trigger the alert rule and the function stays at a single replica.
Future work
Functions can be invoked synchronously, for an instant response to the caller, or asynchronously, using a NATS JetStream queue and an optional callback. Queued invocations are ideal for long running requests, batch processing and background jobs. Queued invocations can also be retried more than efficiently than synchronous invocations since everything required is serialized in the queued message.
See also: Retries for functions
One of our customers asked if it would be possible to scale functions based on the queue depth since it would be more reactive than measuring output metrics like RPS, CPU or connections.
We recently migrated to NATS JetStream for queuing due to the deprecation of NATS Streaming by Synadia. JetStream made it easier for us to export a “queue depth” metric to determine how many requests are queued for each function.
Due to the design of the autoscaler and how we used Prometheus, it was possible to build a Proof of Concept and ship this in a patch to the customer. He was excited about how quick and responsive the scaling was, scaling to match the load in the queue precisely, then scaling to zero after his daily job to import mortgage data was complete.
You can learn more about async invocation and the recent changes we made to the OpenFaaS queuing system in this blog post: The Next Generation of Queuing: JetStream for OpenFaaS
Running some experiments for scaling @openfaas functions based on queue-depth.
— Han Verstraete (@welteki) October 21, 2022
This enables us to scale functions proactively to process the queued work as quickly as possible. pic.twitter.com/EZloVtB9sC
Wrapping up
We gave you an overview of the three new autoscaling modes available in OpenFaaS and how they can be used to scale different types of workloads, but it’s really just the start. You’ll find out what strategy suits your functions best when you start experimenting with them and monitoring how they respond to different traffic patterns using our Grafana dashboards.
The OpenFaaS autoscaler was purpose-built to scale based upon detailed metrics emitted by the functions themselves. This provides a more reactive alternative to the original Community Edition and Kubernetes HPA, which is a generic scaler for generic workloads.
What about scaling to zero? This is another feature that Kubernetes itself doesn’t provide, because it has to be a generic solution for so many kinds of workloads. Instead with OpenFaaS, we have precise knowledge of the functions and can scale them down to free up resources in the cluster, reducing cost and increasing security by reducing the attack surface of running code.
We’ve provided a small set of load tests written with K6 on GitHub, you can use these to try out the various autoscaling modes yourself: openfaas-autoscaler-tests
Learn more in the docs: Docs: Autoscaling.
You may also like:
- How to process your data the resilient way with back pressure
- Generate PDFs at scale on Kubernetes using OpenFaaS and Puppeteer
- Exploring the Fan out and Fan in pattern with OpenFaaS
If you have questions about anything we talked about today, feel free to get in touch with us for a call.

Han Verstraete
Associate Software Developer, OpenFaaS Ltd

Alex Ellis
Founder of @openfaas.
