Queue-Based Scaling is a long awaited feature for OpenFaaS that matches queued requests to the exact amount of replicas almost instantly.
The initial version of OpenFaaS released in 2016 had effective, but rudimentary autoscaling based upon Requests Per Second (RPS) and was driven through AlertManager, a component of the Prometheus project. In 2019, with growing needs of commercial users with long running jobs, we rewrote the autoscaler to query metrics directly from functions and Kubernetes to fine-tune how functions scaled.
OpenFaaS already has a versatile set of scaling modes that can be fine tuned such as: Requests Per Second (RPS), Capacity (inflight connections/concurrency), CPU, and Custom scaling modes. This new mode is specialised to match the needs of large amounts of background tasks and long running processing tasks.
What is Queue-Based Scaling?
Queue-Based Scaling is a new autoscaling mode for OpenFaaS functions. It is made possible by supporting changes that emit queue depth metrics for each function that’s being invoked asynchronously.
This new scaling mode fits well for functions that are:
- Primarily invoked asynchronously
- May have a large backlog of requests
- Need to scale up to the maximum number of replicas as quickly as possible
- Run in batches, bursts, or spikes for minutes to hours
Typical tasks include: Extract, Transform, Load (ETL) jobs, security/asset auditing and analysis, data processing, image processing, video transcoding, and file scanning, backup/synchronisation, and other background tasks.
All previous scaling modes used output metrics from the function to determine the amount of replicas, which can involve some lag as the invocations build up from a few per second, to hundreds or thousands per second.
When using the queue-depth, we have an input metric that is available immediately, and can be used to set the exact number of replicas needed to process the backlog of requests.
A note from a customer
Surge is a lending platform providing in-depth financial analysis, insights and risk management for their clients. They use dozens of OpenFaaS functions to process data in long-running asynchronous jobs. Part of that involves synchronising data between Salesforce.com and Snowflake, a data warehousing solution.
Kevin Lindsay, Principal Engineer at Surge rolled out Queue-Based Scaling for their existing functions and said:
“We just changed the
com.openfaas.scale.typetoqueueand now async is basically instantly reactive, burning through large queues in minutes”
Kevin explained that Surge makes heavy use of Datadog for logging and insights, which charges based upon various factors, including the number of Pods and Nodes in the cluster. So unnecessary Pods, and extra capacity in the cluster means a larger bill, so having reactive horizontal scaling and scale to zero is a big win for them.
Load test - Comparing Queue-Based Scaling to Capacity Scaling
We ran a load test to compare the new Queue-Based Scaling mode to the existing Capacity scaling mode. Capacity mode is also effective for asynchronous invocations, and functions that are invoked in a hybrid manner (i.e. a mixture of both synchronous and asynchronous invocations).
For the test, we used hey to generate 1000 invocations of the sleep function from the store. Each invocation had a variable run-time of 10-25s to simulate a long-running job.
You will see a number of retries in the graphs emitted as 429 responses from the function. This is because we set a hard-limit of 5 inflight connections per replica to simulate a limited or expensive resource such as API calls or database connections.
First up - Capacity Scaling:
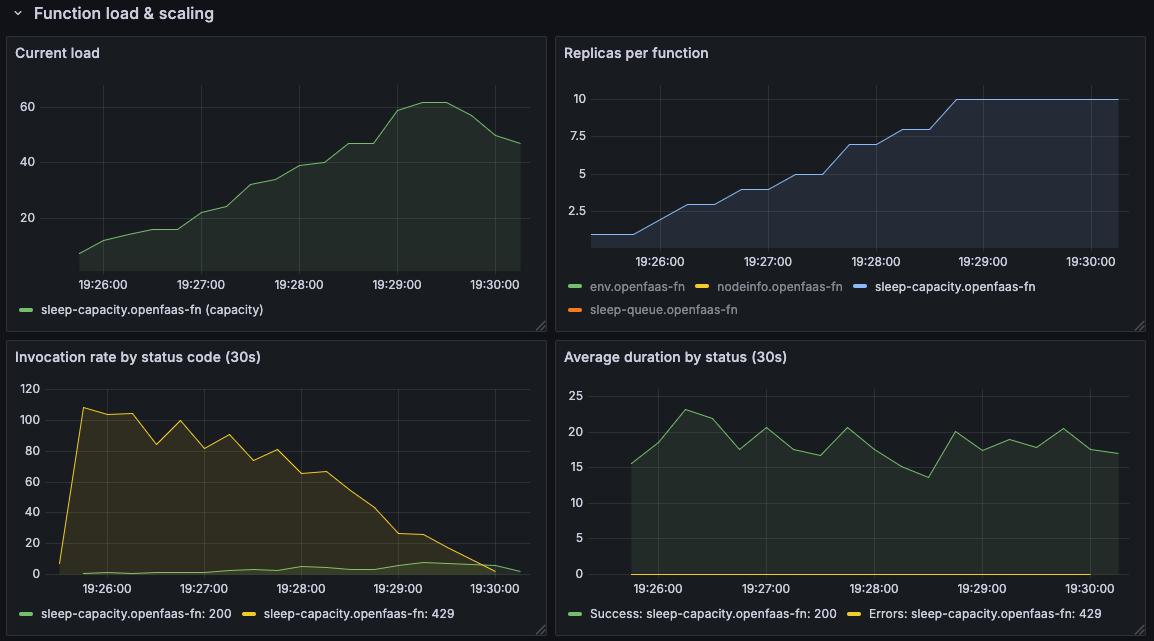
We see that the load starts low, and builds up as the number of inflight connections increases, and the autoscaler responds by adding more replicas.
It is effective, but given that all of the invocations are asynchronous, we already had the data to scale up to the maximum number of replicas immediately.
Next up - Queue-Based Scaling:
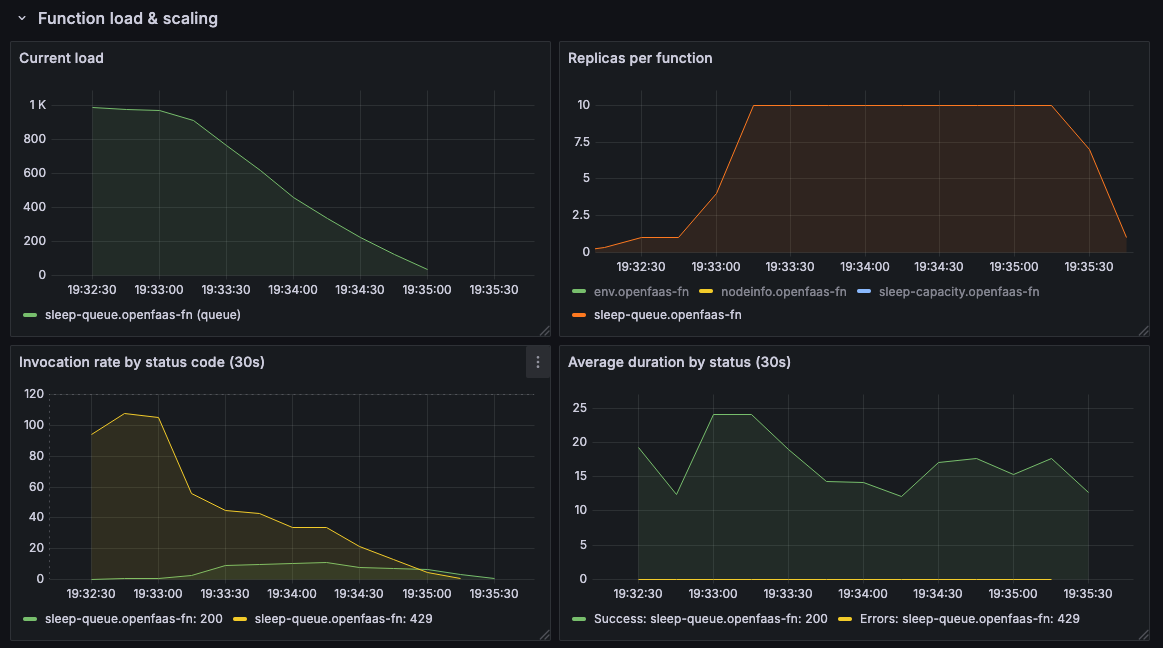
The load metric in this screenshot is the equivalent of the pending queue-depth.
We see the maximum number of replicas jump to 10 and remain there until the queue is emptied, which means the load (which is the number of invocations) is also able to start out at the maximum level.
How does it work?
Just like all the other autoscaling modes, basic ranges are set on the function’s stack.yaml file, or via REST API call
A quick recap on scaling modes
One size does not fit all, and to give a quick summary:
- RPS - a default, and useful for most functions that execute quickly
- Capacity - also known as “inflight connections” or “concurrency” - best for long running jobs or those which are going to be limited on concurrency
- CPU - a good fit when RPS/Capacity aren’t working as expected
- Custom - any metric that you can find in Prometheus, or emit from some component of your stack can be used to drive scaling
Demo with Queue-Based Scaling
First, you can set a custom range for the minimum and maximum number of replicas (or use the defaults):
functions:
etl:
labels:
com.openfaas.scale.min: "1"
com.openfaas.scale.max: "100"
Then, you specify whether it should also scale to zero, with an optional custom idle period:
labels:
com.openfaas.scale.zero: "true"
com.openfaas.scale.zero-duration: "5m"
Finally, you can set the scaling mode and how many requests per Pod to target:
labels:
com.openfaas.scale.mode: "queue"
com.openfaas.scale.target: "10"
com.openfaas.scale.target-proportion: "1"
With all of the above, we have a function that:
- Scales from 1 to 10 replicas
- Scales to zero after 5 minutes of inactivity
- For each 10 requests in the queue, we will get 1 Pod
So if you have to scan 1,000,000 CSV files from an AWS S3 Bucket, you could enqueue one request for each file. This would create a queue depth of 1M requests and so the autoscaler would immediately create 100 Pods (the maximum set via the label).
In any of the prior modes, the Queue Worker would have to build up a steady flow of requests, in order for the scaling to take place.
If you wanted to generate load in a rudimentary way, you could use the open source tool hey, to submit i.e. 2.5 million requests to the above function.
hey -d PAYLOAD -m POST -n 2500000 -c 100 http://127.0.0.1:8080/async-function/etl
Any function invoked via the queue-worker can also return its result via a webhook, if you pass in a URL via the X-Callback-Url header.
Concurrency limiting and retrying requests
Queued requests can be limited in concurrency, and retried if they fail.
Hard concurrency limiting can be achieved by setting the max_inflight environment variable i.e. 10 would mean the 11th request gets a 429 Too Many Requests response.
environment:
max_inflight: "10"
Retries are already configured as a system-wide default from the Helm chart, but they can be overridden on a per function basis, which is important for long running jobs that may take a while to complete.
annotations:
com.openfaas.retry.attempts: "100"
com.openfaas.retry.codes: "429"
com.openfaas.retry.min_wait: "5s"
com.openfaas.retry.max_wait: "5m"
Better fairness and efficiency
The previous version of the Queue Worker created a single Consumer for all invocations.
That meant that if you had 10,000 invocations come in from one tenant for their functions, they would likely block any other requests that came in after that.
The new mode creates a Consumer per function, where each Consumer gets scheduled independently into a work queue.
If you do find that certain tenants, or functions are monopolising the queue, you can provision dedicated queues using the Queue Worker Helm chart.
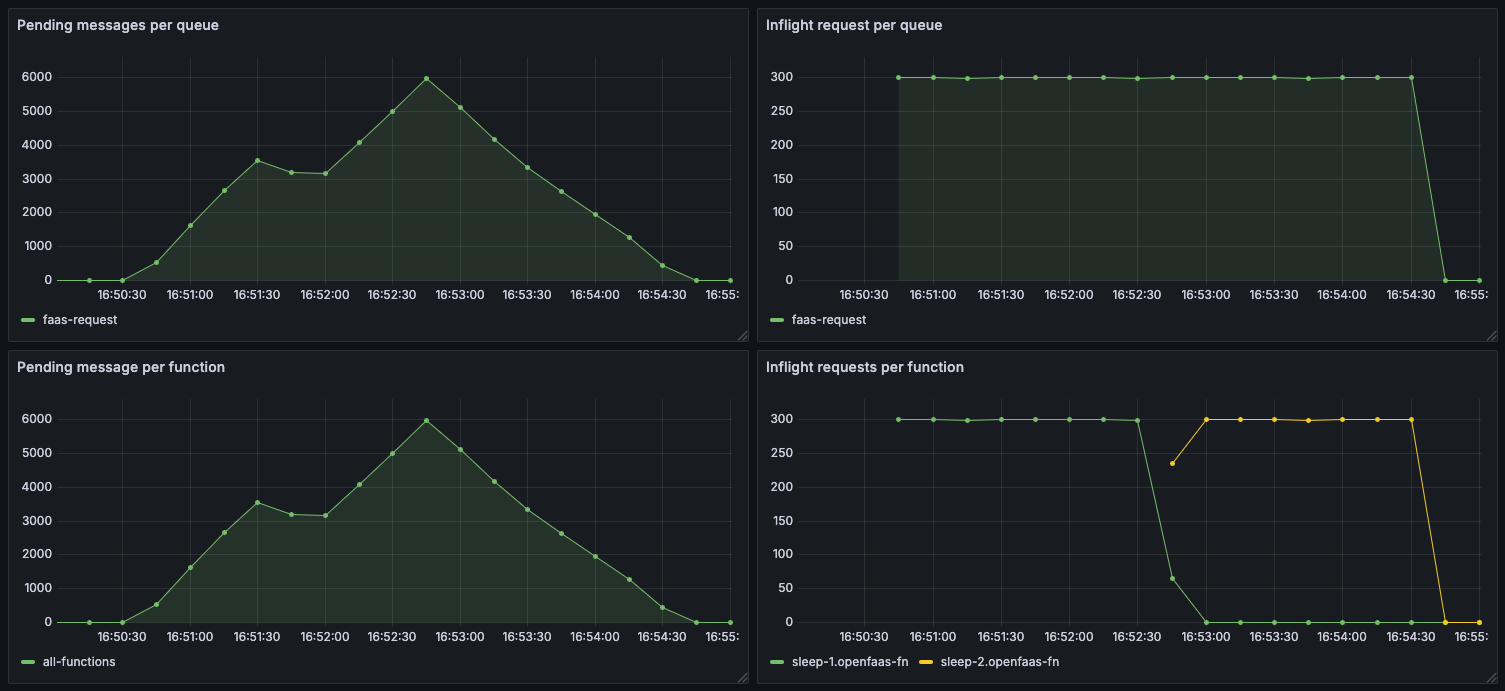
Let’s picture the difference by observing the Grafana Dashboard for the Queue Worker.
In the first picture, we’ll show the default mode “static” where a single Consumer is created for all functions, and asynchronous invocations are processed in a FIFO manner.
The sleep-1 function has all of its invocations processed first, and sleep-2 is unable to make any progress until the first function has been processed.
Next, we show two functions that are invoked asynchronously, but this time with the new “function” mode. Each function has its own Consumer, and so they can be processed independently.
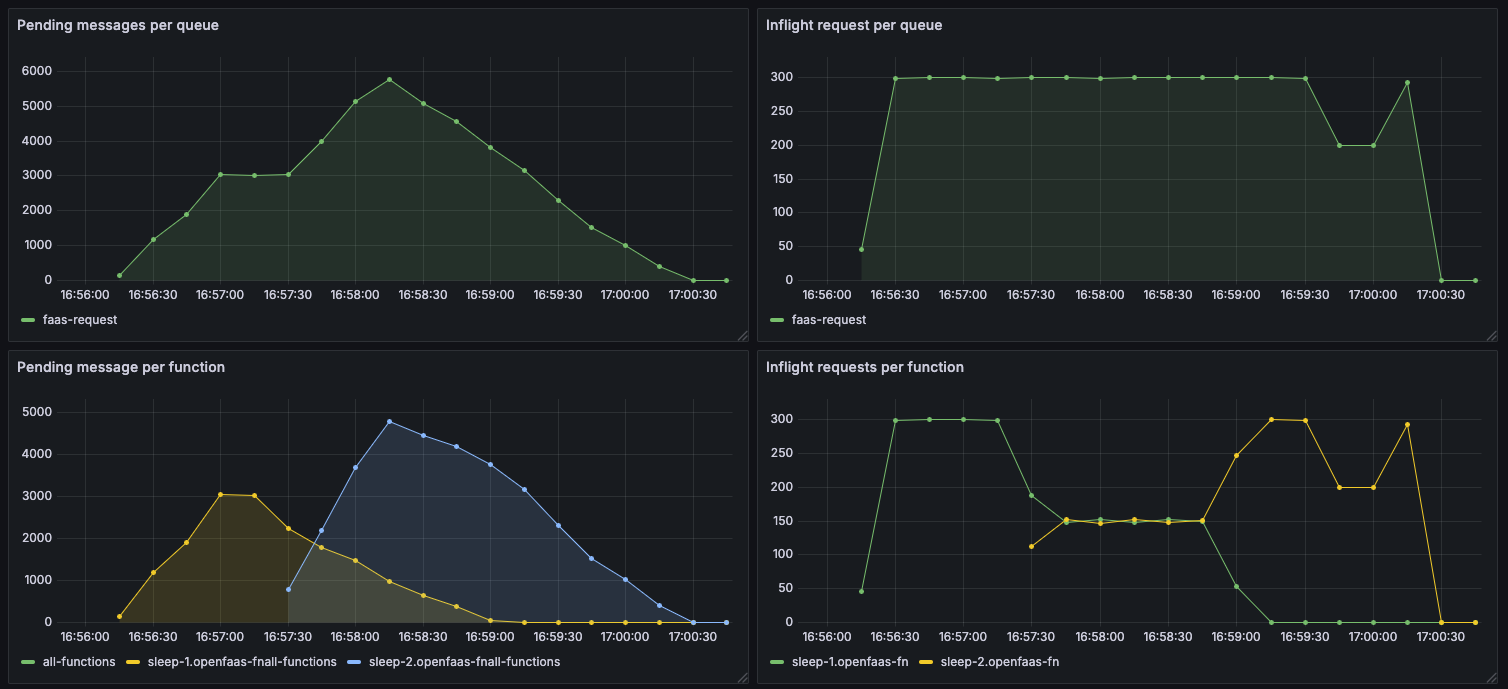
Here, we see that the sleep-1 function is still being processed first, but the sleep-2 function is also able to make progress at the same time.
What changes have been made?
A number of changes have been made to support Queue-Based Scaling:
-
Queue Worker - the component that performs asynchronous invocations
When set to run in “function” mode, it will now create a Consumer per function with queued requests.
It deletes any Consumers once all available invocations have been processed.* Helm chart - new scaling rule and type “queue”
No changes were needed in the autoscaler, however the Helm chart introduces a new scaling rule named “queue”
-
Gateway - publish invocations to an updated subject
Previously all messages were published to a single subject in NATS which meant no metric could be obtained on a per-function basis.
The updated subject format includes the function name, allowing for precise queue depth metrics to be collected.
Note that the 0.5.x gateway will start publishing messages to a new subject format, so if you update the gateway, you must also update the Queue Worker to 0.4.x or later, otherwise the Queue Worker will not be able to consume any messages.
This includes any dedicated or separate queue-workers that you have deployed, update them using the separate queue-worker Helm chart.
How do you turn it all on?
Since these features change the way that OpenFaaS works, and we value backwards compatibility, Queue-Based Scaling is an opt-in feature.
First, update to the latest version of the OpenFaaS Helm chart which includes:
- Queue Worker 0.4.x or later
- Gateway 0.5.x or later
Then configure the following in your values.yaml file:
jetstreamQueueWorker:
mode: function
The mode variable can be set to static to use the previous FIFO / single Consumer model, or function to use the new Consumer per function model.
At the same time, as introducing this new setting, we have deprecated an older configuration option that is no longer needed: queueMode.
So if you have a queueMode setting in your values.yaml, you can now safely remove it so long as you stay on a newer version of the Helm chart.
In the main chart, the jetstreamQueueWorker.durableName field is no longer used or required.
Dedicated queue-workers
If you have dedicated queue-workers deployed, you will need to update them using the separate queue-worker Helm chart.
A new field is introduced called queueName in values.yaml, the default value is not set. When it is not set, the queue will take the name of the stream.
So if you had an annotation of com.openfaas.queue=slow-fns, you would set the queueName like this in values.yaml:
maxInflight: 5
+queueName: slow-fns
mode: static
nats:
stream:
name: slow-fns
consumer:
durableName: slow-fns-workers
upstreamTimeout: 15m
Alternatively, you can leave queueName as empty, or not set it at all, and the name will be taken from nats.stream.name.
The top level setting durableName has now been removed.
You can read more in the README for the queue-worker chart.
Wrapping up
A quick summary about Queue-Based Scaling:
- The Queue-Worker consumes messages in a fairer way than previously
- It creates Consumers per function but only when they have some work to do
- The new
queuescaling mode is reactive and precise - setting the exact number of replicas immediately - Better for multi-tenant deployments, where one tenant cannot monopolise the queue as easily
If you’d like a demo about asynchronous processing or long running jobs, please reach out via the form on our pricing page.
Use-cases:
- Generate PDFs at Scale
- Exploring the Fan out and Fan in pattern
- On Autoscaling - What Goes Up Must Come Down
Docs:

Alex Ellis
Founder of @openfaas.
