In this post I’ll explain how you can now save resources by having OpenFaaS automatically scale functions to zero replicas and back to their minimum replica-level again whenever they are needed. The zero-scale feature consists of scaling up from zero and scaling down to zero, both work very together to provide cost savings and efficient use of resources.
Brief history of auto-scaling
Auto-scaling was first introduced into OpenFaaS in the lead-up to my keynote session at Dockercon 2017 in Austin, Texas. The feature was built using a combination of Prometheus metrics gathered from the gateway component and rules defined in AlertManager. Each time the alert fired, a proportional amount of the maximum amount of replicas would be added and once the alert had been cleared for a period of time the replica count would be reset to the minimum value.
During my Cool Hack @DockerCon triggered a denial of service attack on @github through stars. See the functions here https://t.co/MCFMnqB5X2 pic.twitter.com/cw8fLXiIfW
— Alex Ellis (@alexellisuk) April 20, 2017
The built-in rules are built around the query-per-second or QPS for the function as measured at the gateway. Other rules could be added or customized based upon other factors.
The auto-scaling work can be disabled if you have your own solution, but is useful as a default experience that works with any OpenFaaS back-end, including the Hashicorp Nomad back-end for OpenFaaS or the AWS Fargate backend for OpenFaaS.
When the faas-netes back-end for OpenFaaS was built that meant we could use either the Prometheus/AlertManager solution or the Kubernetes Horizontal Pod Scaler (HPA) and it’s easy to switch between the two.
You can read more about auto-scaling in the OpenFaaS docs.
Introducing Zero-scale
Let’s define “zero-scale” as the idea that a function can be reduced down to zero replicas when idle and brought back to the required amount of replicas when it is needed. The building block for this exists in most container orchestration systems such as Kubernetes and Docker Swarm. When a Kubernetes Deployment is scaled to zero replicas, its Pod will be deleted.
Scale down to zero
OpenFaaS tracks usage metrics on all functions that pass through the gateway component. Prometheus metrics are scraped on a regular interval meaning at any point in time we can query Prometheus and find out whether a function has been idle for a given amount of time. I wrote a component called faas-idler to handle this task - it polls for Prometheus metrics on a regular basis to find functions which have been idle (received no traffic) for a given period of time. This is not the first “idler” to exist and it turns out the OpenShift project has been doing this successfully for several years using a component named service-idler.
Since the original idler was written, we found a number of edge cases in both scaling to zero and back up again, in OpenFaaS Pro - the new autoscaler released in 2021 addresses all the issues we found.
The OpenFaaS REST API already supports scaling a function to N replicas, so the faas-idler just needs to act as a controller to reconcile that state.
If you imagine what this would look like in psuedo code, the following is not far off the actual implementation:
while True:
idle = query_prometheus_for(functions idle over N minutes)
for function in idle:
gateway.scale(0, function)
sleep_for(interval)
Scaling up from zero
Scaling back up again from zero-scale (0/0 replicas) is a slightly more involved problem. Generally if a consumer calls a function which has been idled then there will be no code or service ready to receive the traffic and the response would have be a failure such as HTTP 502/500. A similar problem was solved by the systemd authors with a solution called “socket activation”. With systemd you may have a service (instead of a function) such as ssh. Systemd will listen for connections on port 22 and as soon as one comes in it will forward that connection to a proxy, the proxy starts the sshd process and forwards traffic to it. Atlassian have a blog post showing how to do this Docker containers + systemd. The OpenFaaS implementation takes a similar approach.
Let’s take a real-world example of a function used to send a greeting to new community members on Slack slack-welcome. Whenever someone joins the #general channel, then Slack will send a webhook to our function, but this only needs to run up to a dozen times per day and doesn’t need to consume resources 24/7.
This is what it looks like when someone joins:
By default OpenFaaS will maintain at least one replica of your function so that it is warm and ready to serve traffic at any time with minimal latency. There is a cost involved in scaling from zero, but with some tuning we saw that cost get as low as 1-1.5 seconds.
The zero-scale code for OpenFaaS is implemented in the gateway component. From 0.8.9 the OpenFaaS gateway maintains a cache of all “ready” functions which is refreshed regularly. When a call comes in for a function that has been idled, it is looked up in the map and finds “0” ready replicas. At that point a scaling command will be issued via the REST API and the request will be blocked until the cache of ready functions shows at least one replica has passed its healthcheck and is online for traffic. Then the request is allowed to proceed through.
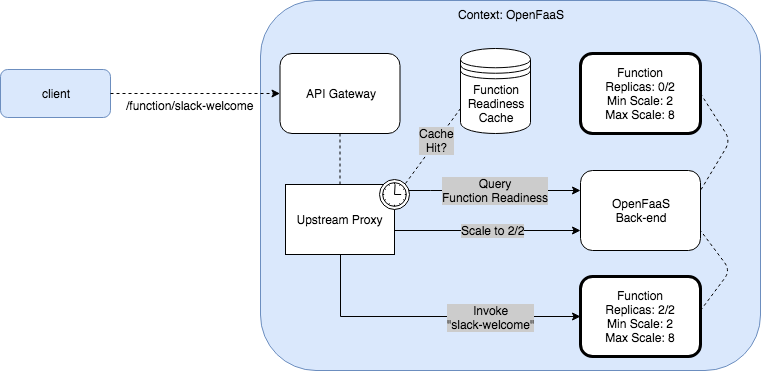
Above: Conceptual diagram showing OpenFaaS scaling our Slack welcome-bot
The scaling up behaviour can be enabled in the OpenFaaS gateway by setting the scale_from_zero flag to true. This can be configured in helm or via editing docker-compose.yml.
This wraps up the introductory blog post on zero-scale in OpenFaaS.
Berndt Jung from VMware has already been making use of zero-scale with OpenFaaS to reduce the size (and cost) of his FaaS dev and test environments on public cloud.
Try it out today
If you’re an OpenFaaS Pro customer, you can try out scale to zero today:

Alex Ellis
Founder of @openfaas.
