Have you heard of the notorious cold-start of serverless? Here’s how you can tune it, or even bypass it completely.
Perhaps you’re an AWS Lambda user and have a cron job to “keep your function warm”? That’s one thing that you’ll not need to do with OpenFaaS because cold-starts are opt-in, rather than compulsory.
Learn how Scale to Zero can reduce your cloud spend, what causes a cold-start in Kubernetes, ways to optimise it, and how to bypass it completely.
Scale to Zero and cloud savings
I recently spoke to a customer who was spending 60,000 USD per month on AWS EC2, and about another 10% of that per month on AWS Lambda. They told me that their costs on EC2 were mainly due to over-provisioning and unused capacity. AWS Lambda had some pros and cons for them, but ultimately, whatever they could move - saved them money on their bills.
So why were they talking to the founder of OpenFaaS - for Kubernetes? Well, they were now getting chased down by their CFO due to the increasing costs of AWS Lambda, and had done some back of a napkin calculations that showed using their existing AWS EKS cluster and OpenFaaS Standard could save them more over the long term.
Scale to Zero works by monitoring traffic going to functions, and removing running instances if they appear to be idle. But how does it save money, especially if you’re running on your own EKS cluster?
It saves money simply by reducing the size and or amount of nodes in the cluster, which ties directly to that expensive EC2 bill.
How else can you save money?
Kevin Lindsay works at Surge and is an expert user of OpenFaaS. He told me that they are using OpenFaaS for all new development and that scale to zero is ultimately important for reducing both the bill for EKS worker nodes, but also for dependent services that are charged on a per-container basis like Datadog. He was able to save his company 75% on their AWS bill by moving to Spot Instances and Scale to Zero combined.
How cold are we talking about?
Now there is an important caveat to scale to zero.
If you scale a function down, you’ll need to scale it back up again to serve a request - this is widely known as a cold-start.
Within a “cold-start” - any number of things could be going on including:
- Pulling the image from a remote registry over the Internet
- Inspecting all the nodes in the cluster to find the best placement
- Starting the Pod and any additional containers (like Envoy) using containerd
- Setting up the Pod’s networking and IP addresses
- Waiting for the Pod to be marked as “Ready” by Kubernetes
Given that a Pod in Kubernetes cannot serve HTTP traffic until it is marked as “Ready”, we end up with a minimum cold-start time of 1-2 seconds for Pod deployed to Kubernetes. And a serverless or FaaS framework is no different, if it uses standard Kubernetes APIs.
In my testing - the typical cold-start (in optimal conditions) for a Kubernetes-based platform like OpenFaaS or Knative is 1-2 seconds. I tested both last week with a minimal Go function that prints out environment variables from a HTTP request. I used a single-node KinD cluster, with the image pre-pulled, and a policy set on the Pod of “IfNotPresent” to avoid pulling the image again. For OpenFaaS, I went one step further and set the readiness probes up to run every 1 second and for the initial probe to run after 1 second (the quickest available).
How can we fine-tune the cold-starts?
In order to bring a function up as quickly as possible, we have to optimize the steps mentioned earlier:
-
Pull the image from a local registry cache, or pre-download all function images to each node
The default Kubernetes scheduler already has the “ImageLocality” plugin set up by default, so Kubernetes will favour nodes where the image is already present.
There are also a few community tools and workarounds to pre-cache images - these range from using a DaemonSet to pull the image onto each node, to peer to peer sharing of images between nodes, to using a local registry cache, even using an in-cluster Redis instance with a key and value for each container layer for near instant access.
But even with all of the above, we’re still going to have a cold-start of 1-2 seconds.
-
Readiness - initialProbeSeconds (runs once at the start) and periodSeconds (runs every X seconds)
With OpenFaaS, you can configure the readiness probe for functions either at the cluster level, or per function.
Helm chart:
faasnetes: readinessProbe: initialDelaySeconds: 1 periodSeconds: 1 timeoutSeconds: 1It should be noted that making every function in the cluster have a one-second readiness probe is going to create additional load.
So by only setting this on the functions that need it, you can reduce the load on the cluster.
stack.yaml:
functions: env: image: ghcr.io/openfaas/env:latest annotations: com.openfaas.ready.http.path: "/_/ready" com.openfaas.ready.http.initialDelay: 1s com.openfaas.ready.http.periodSeconds: 1sYou can check to see if the readiness probe has been configured correctly with the following:
kubectl get deploy/env -n openfaas-fn -o yamlLook in the
readinessProbesection of the Pod’s spec.
What may be outside of our control?
-
Application start-up
Now, just because your Pod came up within 1 second doesn’t mean that it can serve traffic. If you are serving a machine learning model that takes 10 seconds to get fully loaded into memory, then you may in effect have a cold-start of 10 seconds.
Often quoted wisdom to AWS users is to prefer languages which are statically compiled and which start-up quickly like Go. The same may apply to OpenFaaS functions, if they’ve been opted into scale to zero.
-
Side-cars and network drivers
The range of CNI network plugins ranges from spartan to complex. Some of them may take a few seconds to set up the Pod’s networking and IP addresses, depending on whether they run their own control-plane and cluster.
The Istio side-car was the notorious cause of a 16 second cold-start in an early version of Knative.
The CNI option for Istio has reduced the latency, and the new Istio Ambient Mesh which removes Pod-level side-cars may reduce it even further.
-
Round-trip latency
If your function is deployed in a cluster running in us-east-1 and your customers are in Europe, then the cold-start is going to be constant, but to the end-user, the total round-trip time may be longer.
Make sure that you’re measuring the right thing.
Scale from zero timings are available in the logs of the gateway:
kubectl logs -n openfaas deploy/gateway -f -c gateway -
Readiness Probes
By all means, you can send traffic to an endpoint Kubernetes as soon as it has an IP address, but the likelihood of getting a non 2xx response is very high. I know this from experience, when LivePerson who was unhappy with a 1 second cold-start asked us to investigate what could be achieved without using probes.
What are the alternatives to cold-starts?
As we’ve seen, any Pod that gets scaled from 0 to 1 replicas in Kubernetes will take around 1 second in optimal conditions before it can serve traffic.
But what if we could bypass this cold-start?
There are three options
1) Just don’t have a cold start
OpenFaaS was one of the first frameworks to offer a minimum amount of replicas - i.e. 1/1. This warm replica is ready to serve traffic immediately, and will likely be able to handle user-load until additional replicas are brought on.
Cloud vendors like AWS and Azure call this concept “provisioned capacity”
But you are not a cloud vendor, you’re not operating a massive-scale, low margins SaaS where you need to deploy millions of functions.
You’re running your own business. You can chose a minimum number of replicas that makes sense for your business, and you can scale up to meet demand.
2) Use asynchronous - deferred invocations
OpenFaaS has a powerful asynchronous system built around NATS JetStream. Any invocation can be made asynchronously by changing /function/ to /async-function/ in the URL. This will return a 202 Accepted response immediately along with a X-Call-Id header, and the request will be queued up for processing when there is capacity available.
What’s more - all asynchronous invocations are stored in a durable queue, so you can be sure that your request will be processed, even if the function is scaled down to zero.
Detailed metrics show you how many requests are pending, along with the processing rate.
And you can get a call back to another function or HTTP endpoint with the result, if you need it, which can be correlated with the X-Call-Id header.
3) Pre-pull images and fine-tune the probes
As we covered in the previous section, by pre-pulling images to at least one node, the Kubernetes schedule will score that node higher, and the Pod should be scheduled there and started immediately. The readiness probe can be set to run every one second for either the whole cluster or just the functions that need to come online as quickly as possible.
4) The Kernel Freezer
In our version of OpenFaaS designed for single nodes called faasd, the cold start is only a few milliseconds. But why?
Instead of removing all resources allocated when a function is scaled to zero, we put the container into a paused state using a Kernel feature called the freezer. This only stops the CPU from running, but the memory and network remain in place.
Is this actually beneficial to users?
I’d say that using the Kernel Freezer with Kubernetes would be of little benefit. Idle functions are already consuming little to no CPU, so you’re not going to see a difference in consumption. Then, you can’t save money by reducing nodes, which is the main reason we see customers asking us about the commercial version of OpenFaaS.
Troubleshooting the cold-start
As we read in the introduction, every time you invoke a function that is scaled to zero, a chain of events will happen.
If you’re running into problems where some of your invocations are failing - either every time or intermittently, then check your configuration.
1) Istio & Linkerd users
You’ll need to enable two things in the Helm chart.
directFunctions: true
probeFunctions: true
directFunctions defers to the service mesh for service discovery and load balancing, instead of using the Kubernetes API.
probeFunctions attempts to make a call to the function’s readiness path before allowing an invocation to be routed to it.
2) Configure the built-in readiness probe for the function
Check your template and the watchdog version. They should be the latest available on the GitHub releases page. This is usually the first line of the template’s Dockerfile.
FROM ghcr.io/openfaas/of-watchdog:0.9.11 as watchdog
Anyone not using ghcr.io should switch immediately as the Docker Hub images are no longer available.
Try the watchdog’s built-in readiness probe.
Here’s an example that tells both Kubernetes and the OpenFaaS gateway to query /_/ready before allowing an invocation.
com.openfaas.ready.http.path: "/_/ready"
com.openfaas.ready.http.initialDelay: 1s
com.openfaas.ready.http.periodSeconds: 1s
3) Try a custom readiness probe inside the function
If you’re still encountering issues, there may be a race condition between the watchdog starting and your function’s handler coming online.
Try routing the readiness probe to your function’s code:
com.openfaas.ready.http.path: "/ready"
Within your function, you’ll need to add code to handle the /ready path and return a response.
package function
import (
"encoding/json"
"fmt"
"io"
"net/http"
"os"
)
func Handle(w http.ResponseWriter, r *http.Request) {
if r.Path == "/ready" {
w.WriteHeader(http.StatusOK)
return
}
// Your existing function code here
}
The same can be done in any other language such as Python, Java, Node.js and so on.
Seeing it all in action
If you’d like to see a cold-start in action, with all the optimisations we talked about, you can follow along with the steps below.
Create a new cluster using KinD on your computer.
cat > openfaas.yaml <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 31112
hostPort: 31112
EOF
kind create cluster --config openfaas.yaml --name openfaas
This binds the NodePort for the gateway to 31112, so you can access it without needing port-forwarding.
Create a new values-custom.yaml file to be used with the OpenFaaS Chart.
We’ll get a development configuration by turning off async, and having only one replica of each component.
openfaasPro: true
operator:
create: true
faasnetes:
imagePullPolicy: IfNotPresent
clusterRole: true
gateway:
replicas: 1
queueWorker:
replicas: 1
async: false
Note that the imagePullPolicy is set to IfNotPresent so that the images are not pulled from the registry when we scale from zero.
Now, Install the Helm chart and pass in the above values-custom.yaml instead of values-pro.yaml described in the linked page.
The following function.yaml runs an Alpine Linux shell and for each invocation, runs the bash built-in command env. I’m using it because it’s a very small function and quick to load test.
You could also use the below configuration with one of your own functions. If you’re using a stack.yaml file, you can generate a CRD file using the faas-cli generate command.
---
apiVersion: openfaas.com/v1
kind: Function
metadata:
name: env
namespace: openfaas-fn
spec:
name: env
image: ghcr.io/openfaas/alpine:latest
labels:
com.openfaas.scale.zero: "true"
annotations:
com.openfaas.ready.http.path: "/_/ready"
com.openfaas.ready.http.initialDelay: 1s
com.openfaas.ready.http.periodSeconds: 1s
com.openfaas.health.http.initialDelay: 1s
com.openfaas.health.http.periodSeconds: 1s
environment:
fprocess: env
Check that the Pod has the following configured:
- imagePullPolicy: IfNotPresent
- readinessProbe of 1s for initialDelay and periodSeconds
- livenessProbe of 1s for initialDelay and periodSeconds
Check you can reach the initial replica:
curl -s http://127.0.0.1:31112/function/env
Then scale to zero by setting the replica count:
kubectl scale deploy -n openfaas-fn env --replicas=0
Watch until the Pod is completely gone:
kubectl get pods -n openfaas-fn -w
In the background, watch the logs of the gateway:
kubectl logs -n openfaas deploy/gateway -f -c gateway
Then invoke it via curl:
time curl -i -s http://127.0.0.1:31112/function/env
Here’s what I got on my previous-generation Intel NUC:
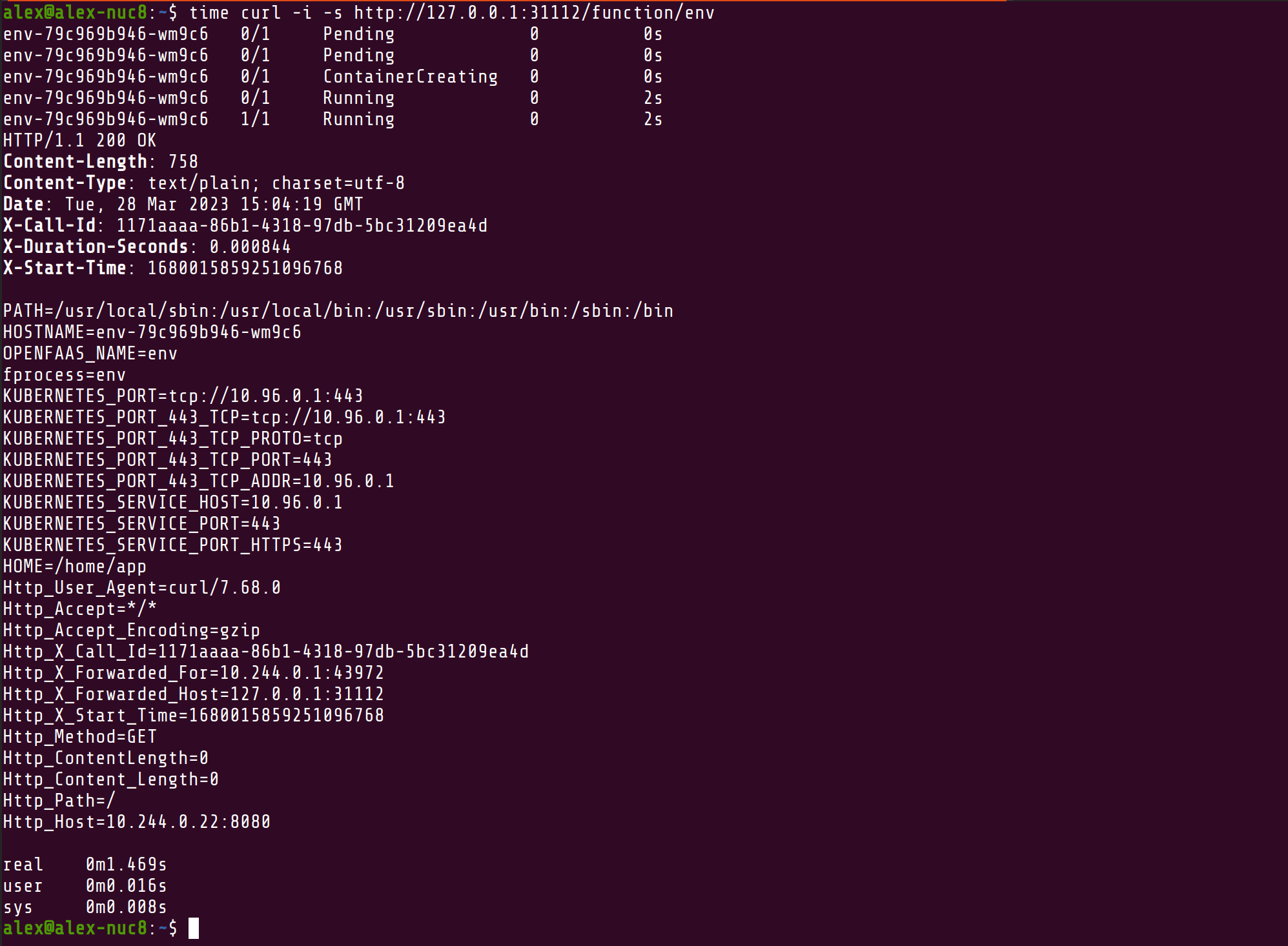
Cold-start timing with a pre-pulled image
We’ve optimised the readiness probe, the pull policy, have the image pre-pulled, have no advanced networking or cross-node communication to be concerned about.
Wrapping up
I’ve written about why Kubernetes has cold-starts in the past, but here I wanted to give us all a refresher and also to compare to other frameworks that leverage Kubernetes for scaling. We’ve also looked at how to fine-tune OpenFaaS Standard in 2023 - because we’ve been investing a lot of time and energy in making auto-scaling better suited to the kinds of workloads that we see our customers deploying.
Should you use Scale to Zero?
Scaling to zero clearly saves money for companies like Surge, but it may not be right for every workload. We explored a number of alternatives to scaling down in the article, including keeping a minimal available set of replicas, or invoking functions asynchronously to hide any scale up latency.
In my opinion, Kubernetes is not currently designed to provide a lower cold-start time than 1s. And any alternative projects tend to involve dubious security trade-offs such as preparing a set of containers, which have their code injected at runtime. This makes them mutable, hard to debug, and error prone.
We often hear from teams who do not want to be locked into a single cloud vendor’s FaaS platform, or to have to deploy both to Kubernetes and something entirely differently. OpenFaaS means you can use your existing experience and insights to build all your workloads for Kubernetes as container images. No surprises, no tricks, just plain old container images and Pods. And where scaling down to zero makes sense for specific workloads, you can do that too, and even save some money at the same time.
Would you like to learn more?
- Compare OpenFaaS versions
- Configure scale to zero for functions
- Tutorial: Custom health and readiness checks for your OpenFaaS Functions
- Rethinking Auto-scaling for OpenFaaS
- Improving long-running jobs for OpenFaaS users
Feel free to reach out to us for a call or demo, or to ask any questions.

Alex Ellis
Founder of @openfaas.
