Alex explores recent changes that makes OpenFaaS more practical for your long running tasks.
Introduction
Serverless functions are often pitched as a way to automate repetitive tasks and transform data. The canonical example is that you have a cloud storage bucket, and every time someone uploads an image, an event is triggered and a thumbnail gets generated and uploaded to another bucket for display on a website.
Having spoken to users and explored problems they’ve faced since 2016, I’ve seen functions used for many different use-cases. You can learn more about that here: Exploring Serverless Use-cases from Companies and the Community
The key learning for me was that one size does not fit all, and whilst some teams such as IconScout did actually want to transform images into different sizes, it was not the only way the platform was being used. In 2017, a community collaborated with us to build a Twitter bot that ran a machine learning model to bring colour back to black and white photos.
Using standard nodes in a GKE cluster meant each invocation took 7-8 seconds, so we scheduled it as an asynchronous invocation.
.@alexellisuk look at 0:40 of this video from major french newspaper LeMonde : don't see something familiar ? #docker & #openfaas powa :) /cc @laurentgrangeau https://t.co/t2c0aaPrYg
— Adrien Blind (@AdrienBlind) November 21, 2017
BT and LivePerson both gave talks at KubeCon to talk about problems that they solved with OpenFaaS. For BT, it was about packaging Machine Learning models for collaboration and shipping as a product that customers could use. For LivePerson, it was about giving their customers a way to extend their chat bot software with custom hooks. At KubeCon, Simon demonstrated how a low chat rating for a customer service rep might trigger an email.
- Accelerating the Journey of an AI Algorithm to Production with OpenFaaS - Joost Noppen, BT PLC & Alex Ellis, OpenFaaS Ltd
- How LivePerson is Tailoring its Conversational Platform Using OpenFaaS - Simon Pelczer, LivePerson & Ivana Yovcheva, VMware
BT’s invocations were long running and heavyweight, whilst LivePerson’s were often very short-lived since they needed to complete within a chat context, but would generate spikes in load on the platform.
When people hear about OpenFaaS for the first time, they often ask me: “Why wouldn’t we just use cloud functions?” and this is a valid and important question.
Most of you should be using cloud functions, and not thinking about running something yourself. If you want to integrate one AWS service with another, then you absolutely should use AWS Lambda, it’s the right tool for the job.
But quite often, cloud functions fall short for any number of reasons such as: limited function upload size, lack of source control integration. One area that is important to Kevin Lindsay from Surge is having a workflow for functions that matches their tightly-tuned software development lifecycle for Kubernetes applications deployed to AWS EKS. Their OpenFaaS functions simply become another Custom Resource and helm chart to manage, rather than the completely orthogonal suite of tools that they would need for AWS Lambda.
OpenFaaS functions are packaged in container images and run as normal Pods using HTTP for the input and output. This makes it easier to debug them than cloud solutions.
Kevin’s team simply stand up a local cluster with KinD an can test their work end-to-end before moving it to a live staging environment on the cloud.
What changed and why did we need it?
As part of a consulting project for Surge, we explored a number of issues the team faced with long running invocations. It turned out that when a function was scaled down, it could drop some invocations, but only if they took more than 30 seconds. Parts of OpenFaaS already handled a safe and graceful shutdown sequence, but Kevin found that the default Termination Grace Period we set on pods was too short for his work.
After defining an issue and giving a demo that we could use to reproduce the problem, I started work on a number of changes. The first change was not the one I expected to make.
I first needed to update the OpenFaaS watchdog. The watchdog is a component that helps end-users satisfy the health checks required by Kubernetes, and to add a HTTP interface to CLIs and languages without native support such as: bash, COBOL, PowerShell etc.
The watchdog also implemented a graceful shutdown sequence which involved waiting for an arbitrary amount of time before shutting down, to enable in-flight requests to complete. This was not a problem when the Termination Grace Period was limited to 30 seconds, because the maximum time a Pod would stay in a Terminating was 30 seconds. With a configurable Termination Grace Period, the watchdog could keep a Pod in a terminating status for minutes or even hours, depending on what value was set.
So I made use of the Shutdown function on Go’s standard HTTP server. It’s a blocking operation, and so it meant we could remove the arbitrary wait period and shutdown as soon as there were no requests left in-flight. If the container was already idle, it could shutdown immediately, making OpenFaaS scaling more responsive.
Shutdown gracefully shuts down the server without interrupting any active connections. Shutdown works by first closing all open listeners, then closing all idle connections, and then waiting indefinitely for connections to return to idle and then shut down. If the provided context expires before the shutdown is complete, Shutdown returns the context’s error, otherwise it returns any error returned from closing the Server’s underlying Listener(s).
See also: func (*Server) Shutdown
You can see the PR here: openfaas/of-watchdog Speed up shutdown according to number of connections #125
The next problem to solve was the configuration of the Termination Grace Period. I’ve often heard users complain that OpenFaaS has too many timeout values, and I sympathise with this viewpoint. I consulted the other regular contributors and we agreed that using one of the existing timeout values to set the Termination Grace Period was the best option.
Now, whenever you set a write_timeout environment variable for your function, it will be used by the OpenFaaS Pro operator to set the Termination Grace Period to this value plus jitter. But that’s not the only change required - a coordinated set of changes make this work correctly.
Readiness is also a key change to make sure traffic is sent to the correct Pods during rolling updates and autoscaling. See also: Custom health and readiness checks for your OpenFaaS Functions
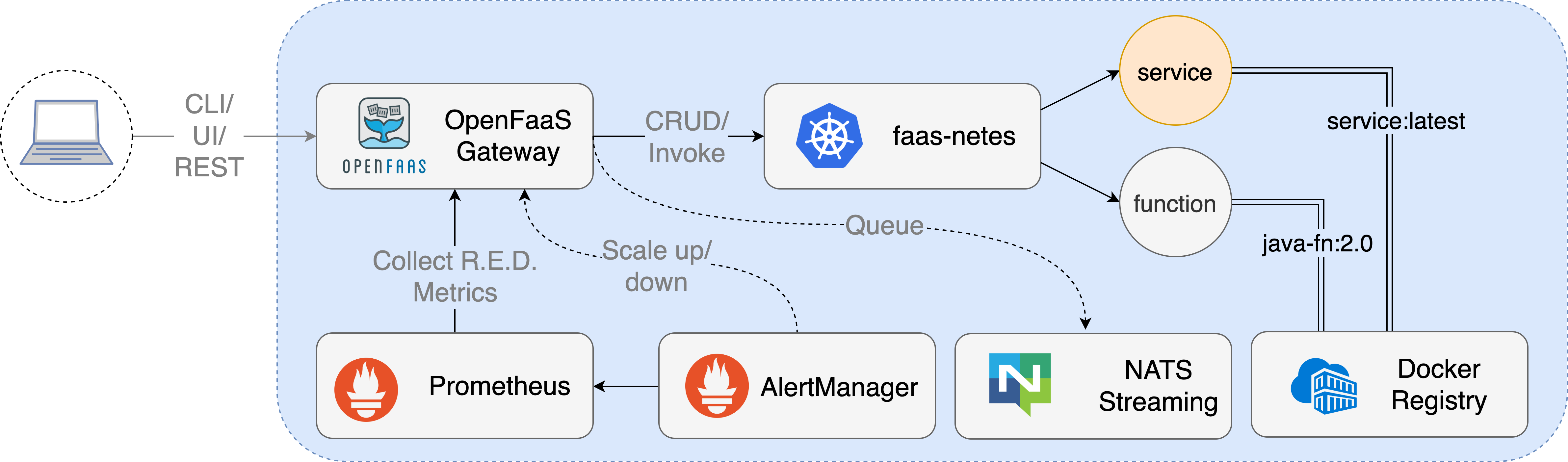
OpenFaaS Conceptual Architecture showing the separation of concerns between the gateway, queueing, metrics and the Kubernetes operator.
So what does this look like with an example?
I created a tutorial to explain how to set up Expanded timeouts which is also referenced in the troubleshooting guide. It turns out that the maximum timeout for cloud functions can be so prohibitive that many users turn to projects like OpenFaaS for help.
git clone https://github.com/alexellis/go-long
cd go-long
faas-cli deploy --filter go-long
cat stack.yaml
functions:
go-long:
lang: golang-middleware
handler: ./go-long
image: alexellis2/go-long:0.3.0
environment:
write_timeout: 2m30s
read_timeout: 2m
exec_timeout: 2m
handler_wait_duration: 1m30s
healthcheck_interval: 5s
annotations:
topic: "pipeline.subscription"
labels:
com.openfaas.scale.min: 1
com.openfaas.scale.max: 1
The test function’s handler is written in Go and reads the handler_wait_duration environment variable to determine the wait period to simulate.
Note that
handler_wait_durationis not built into OpenFaaS, but is just a way for us to configure our test function.
package function
import (
"fmt"
"log"
"net/http"
"os"
"time"
)
func Handle(w http.ResponseWriter, r *http.Request) {
if r.Body != nil {
defer r.Body.Close()
}
sleepVal := os.Getenv("handler_wait_duration")
sleepDuration, _ := time.ParseDuration(sleepVal)
sleepDurationStr := sleepDuration.String()
log.Printf("Start sleep for: %s\n", sleepDurationStr)
time.Sleep(sleepDuration)
log.Printf("Sleep done for: %s\n", sleepDurationStr)
w.WriteHeader(http.StatusOK)
w.Write([]byte(fmt.Sprintf("Had a nice sleep for: %s", sleepDuration.String())))
}
After deploying it, we can then invoke it using the hey HTTP load testing tool. Note that it’s important to increase its timeout to a suitable number otherwise it will cancel the connections.
hey -c 5 \
-n 10 \
-t 125 \
http://127.0.0.1:8080/function/go-long
Once the invocations are started, trail the logs of the function:
faas-cli logs go-long --tail
Then scale the function to zero replicas to simulate a scale down event:
kubectl scale -n openfaas-fn deploy/go-long --replicas=0
You’ll then see the watchdog does two things:
1) It marks the healthcheck endpoint as unhealthy and then waits for healthcheck_interval. Why? So that Kubernetes stops sending new requests to the function. The function’s endpoint will be removed from the pool of valid IP addresses.
2) It then calls Go’s shutdown method which stops any new requests from being accepted and blocks until active requests have completed.
This is what it looks like in practice, with all requests processed just as we wanted.
2021/11/05 12:08:36 Version: 0.9.0 SHA: aeccaceaff99972711ed5130083c9a925cda5fe1
2021/11/05 12:08:36 Forking: ./handler, arguments: []
2021/11/05 12:08:36 Started logging: stderr from function.
2021/11/05 12:08:36 Started logging: stdout from function.
2021/11/05 12:08:36 Watchdog mode: http
2021/11/05 12:08:36 Timeouts: read: 2m0s write: 2m30s hard: 2m0s health: 5s
2021/11/05 12:08:36 Listening on port: 8080
2021/11/05 12:08:36 Writing lock-file to: /tmp/.lock
2021/11/05 12:08:36 Metrics listening on port: 8081
The initial 4 requests are sent by hey:
2021/11/05 12:09:25 Start sleep for: 1m30s
2021/11/05 12:09:25 Start sleep for: 1m30s
2021/11/05 12:09:25 Start sleep for: 1m30s
The watchdog waits for the configured 5s health timeout:
2021/11/05 12:14:13 SIGTERM: no new connections in 5s
2021/11/05 12:14:13 Removing lock-file : /tmp/.lock
2021/11/05 12:14:13 [entrypoint] SIGTERM: no connections in: 5s
The shutdown endpoint is called to allow the work to drain:
2021/11/05 12:14:18 No new connections allowed, draining: 5 requests
Then we see the invocations complete:
2021/11/05 12:15:39 Sleep done for: 1m30s
2021/11/05 12:15:39 Sleep done for: 1m30s
2021/11/05 12:15:39 Sleep done for: 1m30s
2021/11/05 12:15:39 Sleep done for: 1m30s
2021/11/05 12:15:39 Sleep done for: 1m30s
Finally the container exits:
2021/11/05 12:15:39 [entrypoint] Exiting.
2021/11/05 12:15:39 Exiting. Active connections: 0
Just as expected, hey now reports 100% success:
hey -c 5 -n 10 -t 125 http://127.0.0.1:8080/function/go-long
Summary:
Total: 189.4344 secs
Slowest: 94.7517 secs
Fastest: 94.6820 secs
Average: 94.7169 secs
Requests/sec: 0.0528
Total data: 270 bytes
Size/request: 27 bytes
Response time histogram:
94.682 [1] |■■■■■■■■■■■■■
94.689 [1] |■■■■■■■■■■■■■
94.696 [0] |
94.703 [0] |
94.710 [0] |
94.717 [3] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
94.724 [3] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
94.731 [0] |
94.738 [0] |
94.745 [0] |
94.752 [2] |■■■■■■■■■■■■■■■■■■■■■■■■■■■
Latency distribution:
10% in 94.6825 secs
25% in 94.7127 secs
50% in 94.7208 secs
75% in 94.7512 secs
90% in 94.7517 secs
0% in 0.0000 secs
0% in 0.0000 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0001 secs, 94.6820 secs, 94.7517 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0000 secs
req write: 0.0000 secs, 0.0000 secs, 0.0001 secs
resp wait: 94.7166 secs, 94.6816 secs, 94.7516 secs
resp read: 0.0001 secs, 0.0000 secs, 0.0002 secs
Status code distribution:
[200] 10 responses
How long can you go? The answer is that you are only going to be limited by the settings that you choose for your function and OpenFaaS installation. If you are going over around 60 seconds, then it may be advisable to use asynchronous invocations instead.
Wrapping up
The changes that we covered make OpenFaaS much more practical for long running jobs over 30 seconds in duration, where you expect some scaling to take place. If your tasks never scaled, then it’s unlikely that you would have lost any work in progress. A couple of our users moved to spot instances to reduce their cloud spend, which means that functions may be terminated or moved around in the cluster. This change makes the project more durable and stable for long running functions.
You may also be interested in triggering jobs or functions via Kafka. We recently helped Surge to tune one of their weekly jobs that pulls 2M records from Confluent Cloud to complete concurrently using OpenFaaS and go. See also: Event-driven OpenFaaS with Managed Kafka from Aiven
Functions can also be triggered from cron for regular tasks and automation. Find out more: Scheduling function runs with cron
Finally, I wanted to clarify that long running functions do not need to be run synchronously. They can be run asynchronously and even given a callback URL to be notified with the result when they complete.
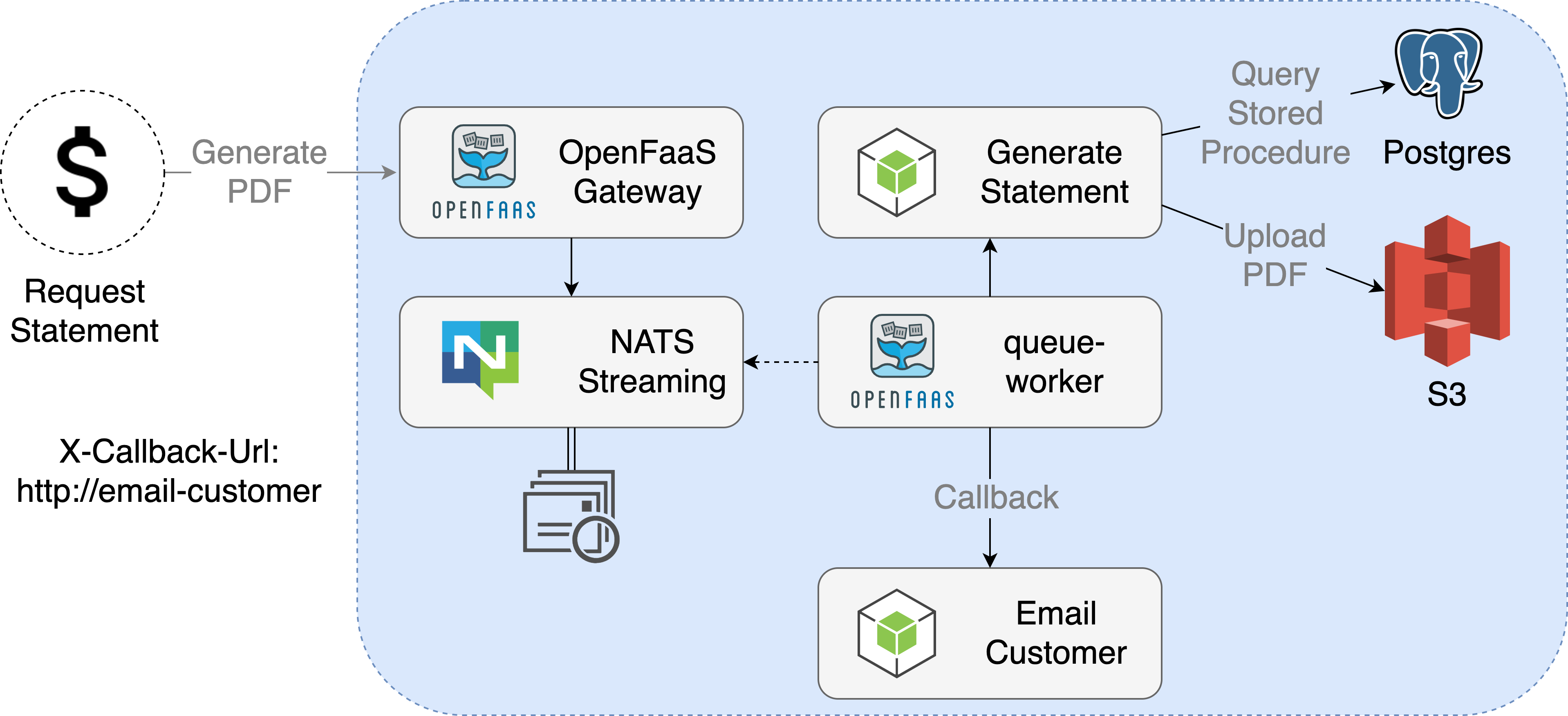
An example of the asynchronous function callback
We recently released a new OpenFaaS Pro queue-worker which decreases verbosity of logs to prevent leaking of sensitive information and to add retries with an exponential backoff. This is particularly useful when coupled with concurrency limiting in a function for tasks like Web scraping with Puppeteer or inference from machine learning models.
I’d like to thank Surge for sponsoring this work and for helping to give feedback that we used to improve OpenFaaS and OpenFaaS Pro.
To learn more about timeouts, cron, logs and asynchronous timeouts, pick up a copy of the Official OpenFaaS manual: Serverless for Everyone Else
If you’d like to know more about anything that I covered today for your team, then feel free to reach out to me at: alex@openfaas.com. Alternatively, you can apply for a trial of OpenFaaS Pro and learn about our commercial services at openfaas.com/support

Alex Ellis
Founder of @openfaas.
