Learn how to run headless browsers on Kubernetes with massive scale using OpenFaaS and Puppeteer.
Intro from Alex:
We had a call with a team from Deel (an international payroll company) who told us they’d recently migrated their PDF generation functions from AWS Lambda to Kubernetes. They told us that AWS Lambda scaled exactly how they wanted, despite its high cost. Then, after moving to Kubernetes, they started to run into various problems scaling headless Chrome and it is still a pain point for them today.
This article shows how we approached the problem using built-in features of OpenFaaS - connection-based (aka capacity), hard limits (aka max_inflight) and a flexible queuing system that can retry failed invocations.
If you follow the instructions, you’ll be able to scale out headless chrome for e2e testing, PDF generation or any other kind of automation that you need, without worrying about reliability.
There are multiple options to generate PDF inside a function but an easy way is to turn a web page into a PDF file. We are going to use puppeteer for this. Puppeteer loads a “headless-chrome” browser and provides an API to automate interacting with the browser. The API can be used to generate PDFs or images from a page or automate navigation and extract information.
Using Puppeteer with OpenFaaS has been covered in one of our previous blog posts: Web scraping that just works with OpenFaaS with Puppeteer.
In this post we are going to focus on how you can make it scale to handle generating hundreds of PDFs.
Walkthrough
In this section we will walk you through the steps to set up two functions for generating PDFs from web pages.
The first function, called page-to-pdf, can be invoked with a URI and will:
- Start a headless browser with Puppeteer
- Navigate to that page
- Create a PDF and return the binary stream as its response
The second function, gen-pdf, is used to initialize the workflow. It can be invoked with a list of URIs and will:
- Invoke the PDF generation function for each URI
- Listen for results to be posted back to its
/saveendpoint - Save the generated PDF in an S3 bucket.
How to generate a PDF from a web page
First of all, let’s just recap on how to create a function with a headless web browser, so we can do automation testing, image/PDF generation and for scraping websites.
We will create a function using the puppeteer-nodelts template and name this function page-to-pdf
# Set to your Docker Hub account or registry address
export OPENFAAS_PREFIX=""
faas-cli template store pull puppeteer-nodelts
faas-cli new \
--lang puppeteer-nodelts page-to-pdf \
--prefix $OPENFAAS_PREFIX
You can now edit ./page-to-pdf/handler.js and make it return a PDF.
'use strict'
const puppeteer = require('puppeteer')
module.exports = async (event, context) => {
let browser
let page
browser = await puppeteer.launch({
args: [
// Required for Docker version of Puppeteer
'--no-sandbox',
'--disable-setuid-sandbox',
'--no-zygote',
'--single-process',
// This will write shared memory files into /tmp instead of /dev/shm,
// because Docker’s default for /dev/shm is 64MB
'--disable-dev-shm-usage'
]
})
const browserVersion = await browser.version()
console.log(`Started ${browserVersion}`)
page = await browser.newPage()
uri = event.body.uri
const response = await page.goto(uri)
console.log("OK","for",uri,response.ok())
const pdf = await page.pdf({ format: 'A4' })
await browser.close()
return context
.status(200)
.headers({"Content-Type": "application/pdf", "X-Page-Uri": uri})
.succeed(pdf)
}
Note that we also set a header X-Page-Uri with the uri of the page on the response. This header will be used later when we create a second function to upload the response to an S3 bucket.
Deploy the page-to-pdf function to OpenFaaS
faas-cli up -f page-to-pdf.yml
You can try out the function with curl. This should save a pdf of the OpenFaaS documentation home page.
export OPENFAAS_URL="http://127.0.0.1:8080"
curl $OPENFAAS_URL/function/page-to-pdf \
-d '{ "uri": "https://docs.openfaas.com"}' \
-H "Content-Type: application/json" \
--output "openfaas.pdf"
Prepare your S3 bucket
The generated PDFs can be stored in an S3 bucket. To run this example yourself you will need to create an Amazon S3 bucket
We used the aws-cli to create a new bucket named of-demo-pdf-gen.
aws s3api create-bucket --bucket of-demo-pdf-gen --region eu-central-1
The function needs access to AWS credentials to use the bucket. faas-cli can be used to add secrets to your cluster that can be accessed within OpenFaaS functions.
Save your AWS access key Id and secret in separate files and create two new secrets with the faas-cli.
faas-cli secret create s3-key --from-file aws_access_key_id.txt
faas-cli secret create s3-secret --from-file aws_secret_access_key.txt
See also: Using secrets in OpenFaaS
How to scale out the PDF generation and store the results
We’ll create a second function with Node.js.
It’ll be invoked in two ways:
- With a JSON payload containing a list of web pages to
/We’ll schedule a number of async invocations to the originalpage-to-pdffunction - With the result from
page-to-pdfto/saveWe’ll assume anything coming to this path with a HTTP POST is a PDF for us to save to S3
It’s best to rename the YAML file for your functions to stack.yaml, which means the various faas-cli commands will work without a -f argument.
faas-cli new pdf-gen --lang node17 --append stack.yaml
Edit the stack.yaml file to include the names of the secrets used for S3 and update the environment variable s3_bucket with the bucket’s name.
Note that we also set two additional environment variables RAW_BODY and MAX_RAW_SIZE. These are required to receive the generated PDFs on the /save endpoint.
pdf-gen:
lang: node17
handler: ./pdf-gen
image: welteki2/pdf-gen:latest
secrets:
- s3-key
- s3-secret
environment:
s3_bucket: of-demo-pdf-gen
RAW_BODY: true
MAX_RAW_SIZE: 40Mb
Edit gen-pdf/handler.js:
'use strict'
const { Upload } = require("@aws-sdk/lib-storage")
const { S3Client } = require("@aws-sdk/client-s3")
const axios = require('axios').default
const fsPromises = require('fs').promises
const crypto = require('crypto');
let s3Client
let bucketName = process.env.s3_bucket || "of-demo-pdf-gen"
async function initS3() {
if (s3Client) return
let accessKeyId = await fsPromises.readFile('/var/openfaas/secrets/s3-key', 'utf8')
let secretAccessKey = await fsPromises.readFile('/var/openfaas/secrets/s3-secret', 'utf8')
s3Client = new S3Client({ region: "eu-central-1", credentials: { accessKeyId, secretAccessKey } })
}
module.exports = async (event, context) => {
await initS3()
if (event.path === '/save') {
if (event.headers["content-type"] === "application/pdf") {
let uri = event.headers["x-page-uri"]
console.log(`Received pdf of: ${uri}`)
const hash = crypto.createHash('sha256').update(uri).digest('hex');
const key = `${hash}.pdf`
const upload = new Upload({
client: s3Client,
params: {
Bucket: bucketName,
Key: key,
Body: event.body,
ContentType: "application/pdf",
Metadata: { uri }
},
})
await upload.done()
console.log(`Saved as: ${key}`)
return context.status(200).succeed()
}
return context.status(400).fail()
}
let body = JSON.parse(event.body)
let pages = body.pages
console.log("Submitting pages")
pages.forEach(async (uri) => {
const res = await axios.post(
"http://gateway.openfaas:8080/async-function/page-to-pdf",
{ uri },
{ headers: { 'X-Callback-Url': 'http://gateway.openfaas:8080/function/pdf-gen/save' } }
)
})
return context
.status(202)
.succeed()
}
The function invokes page-to-pdf asynchronously and sets the X-Callback-Url header to receive the result once it has finished processing. The reason we want to invoke the functions using its async endpoint is so that we can make use of the built in retry mechanism of OpenFaaS. We will see how this works in the next sections.
To try out the workflow save some web page URLs in json file, pages.json, and invoke the gen-pdf function with curl:
{
"pages": [
"https://docs.openfaas.com"
"https://docs.inlets.dev",
]
}
curl -i $OPENFAAS_URL/function/pdf-gen -d @pages.json -H "Content-Type: application/json"
HTTP/1.1 202 Accepted
Content-Length: 0
Content-Type: application/json
Date: Wed, 05 Oct 2022 11:57:42 GMT
X-Call-Id: 39d0d02c-491d-4833-b7ea-633e289e01a6
X-Duration-Seconds: 0.032700
X-Start-Time: 1664971062806019972
When you look at the logs for the gen-pdf function you can see the pages are submitted and the save endpoint is called with the generated PDF for each URL.
pdf-gen-d7c57ff8b-lp8s8 pdf-gen Submitting pages
pdf-gen-d7c57ff8b-lp8s8 pdf-gen 2022/10/05 11:57:42 POST / - 202 Accepted - ContentLength: 0
pdf-gen-d7c57ff8b-lp8s8 pdf-gen Received pdf of: https://docs.openfaas.com
pdf-gen-d7c57ff8b-lp8s8 pdf-gen Saved as: 57e02fedbbdc98a8449193ee4a5268c7ccf6bf113bc64ce4d34118775e8412b9.pdf
pdf-gen-d7c57ff8b-lp8s8 pdf-gen 2022/10/05 11:57:45 POST /save - 200 OK - ContentLength: 0
pdf-gen-d7c57ff8b-lp8s8 pdf-gen Received pdf of: https://docs.inlets.dev
pdf-gen-d7c57ff8b-lp8s8 pdf-gen Saved as: b9f84c4e28ac597bef927b1ec3411c4e22056ebd3a06b1ff20a81cf919edf17f.pdf
pdf-gen-d7c57ff8b-lp8s8 pdf-gen 2022/10/05 11:57:48 POST /save - 200 OK - ContentLength: 0
You should be able to find the PDFs using the AWS S3 console.
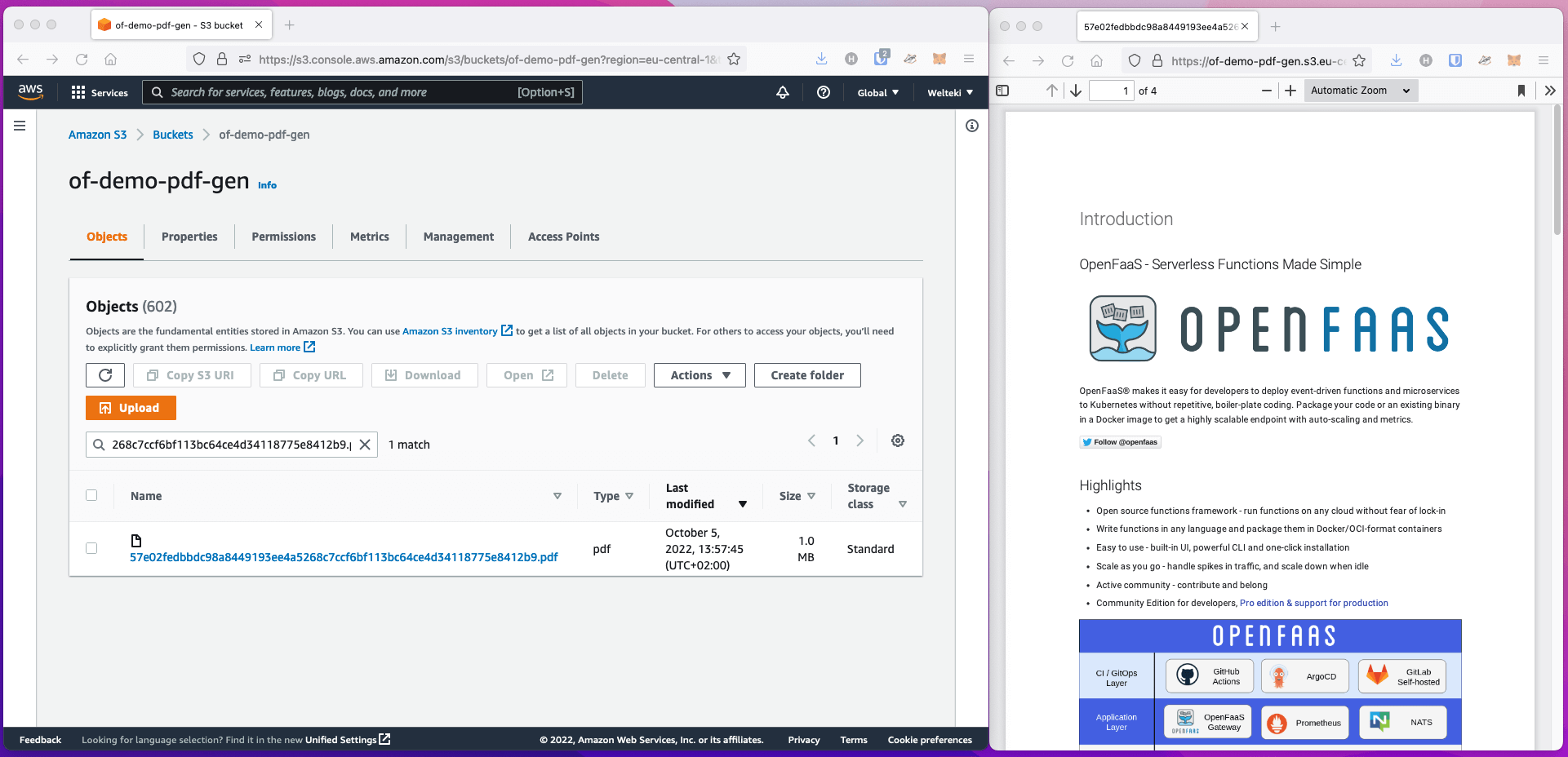
AWS S3 Console with generated PDF
Prevent overloading the function
Each replica of the PDF generation function can only run so many browsers or browser tabs at once. This is where people we talk to tend to struggle. Kubernetes doesn’t implement any kind of request limiting for applications, but OpenFaaS can help here.
So to prevent overloading the Pod, we can set a hard limit on the number of concurrent requests the function can handle. This is a hard limit.
We can for example set a limit of 1 by setting the max_inflight environment variable. Any subsequent requests would be dropped and receive a 429 response. This assumes the producer can buffer the requests to retry them later on. Fortunately, when using async in OpenFaaS Pro, our queue-worker does just that, you can learn how here: How to process your data the resilient way with back pressure
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
page-to-pdf:
lang: puppeteer-nodelts
handler: ./page-to-pdf
image: welteki2/page-to-pdf:latest
environment:
max_inflight: 1
annotations:
com.openfaas.ready.http.path: /_/ready
Note: after changing any value in an OpenFaaS YAML file, you must run faas-cli deploy for the change to take effect.
When setting a concurrency limit on a function traffic may go to Pods which are overloaded, instead of Pods that are ready. To optimize throughput we can use the com.openfaas.ready.http.path annotation to configure a Kubernetes readiness probe for the /_/ready endpoint on our function. This way Kubernetes can route traffic away from the busy Pods which have reached the concurrency limit.
See also: Custom health and readiness checks for your OpenFaaS Functions
Buffer and retry requests
The OpenFaaS Pro queue-worker has built in support for retries. By using this retry mechanism we can make sure all our requests to the PDF generation function are processed even when the function cannot accept any more connections due to the max_inflight setting, or too few replicas of the page-to-pdf function.
The queue-worker and retries configuration can be set in the values.yaml file for the OpenFaaS chart.
queueWorker:
maxInflight: 5
queueWorkerPro:
maxRetryAttempts: "150"
maxRetryWait: "4s"
initialRetryWait: "2s"
httpRetryCodes: "408,429,500,502,503,504"
Any failed requests will be retried using an exponential back-off algorithm. In this case we wait for a maximum of 4 seconds when retrying requests.
Getting the optimal retries configuration for you workload might require some experimentation.
See also retries
By setting queueWorker.maxInflight to 5 we tell the queue-worker to allow a maximum of 5 concurrent requests. This value was selected to prevent overloading the pdf generation function beyond the maximum scale it can reach.
While the function has been limited to handle a single request at once it would make sense to also limit the queue-worker to send it only one request at a time. However, in the next section we are going to configure autoscaling so that our system can scale to a maximum capacity of 5 concurrent requests.
See also parallelism for async requests
By default OpenFaaS comes with a single shared queue for all functions. To be able to optimize the queue configuration for PDF generation a dedicated additional queue can be deployed.
See also: queue-worker helm chart
Autoscaling the page-to-pdf function
To prevent overloading the PDF generation function we gave it a hard limit using max_inflight. This of course greatly limits the number of PDFs we can generate simultaneously. Our function can be scaled horizontally to increase this number. OpenFaaS has different scaling modes available for functions. One of them is the capacity mode which scales functions based upon inflight requests. This makes it very suitable for scaling functions which can only handle a limited number of requests at once.
Autoscaling can be configured via labels on the functions. Modify the stack.yaml file and add the scaling labels to the page-to-pdf function:
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
page-to-pdf:
lang: puppeteer-nodelts
handler: ./page-to-pdf
image: welteki2/page-to-pdf:latest
environment:
max_inflight: 1
labels:
com.openfaas.scale.min: 1
com.openfaas.scale.max: 5
com.openfaas.scale.target: 1
com.openfaas.scale.type: capacity
com.openfaas.scale.target-proportion: 0.7
This will launch a maximum of 5 Pods, each capable of launching one browser at a time.
If you set max_inflight to 2 and com.openfaas.scale.max to 10, you’d have a maximum amount of browsers of 20 at any one time.
See also: OpenFaaS autoscaling
Let’s generate those PDFs
To test if the workflow scales we will invoke the gen-pdf function again but this time we pass in a list of 600 pages.
The OpenFaaS Grafana dashboard shows how the page-to-pdf function is scaled up to the configured maximum replicas as the load increases.
The graph for the invocation rate shows how there initially are a lot of 429 responses but as more replicas of the pdf generation functions are added the number of 429 responses drops. The queue-worker automatically retries these requests so that all PDFs can be generated and no records are lost.
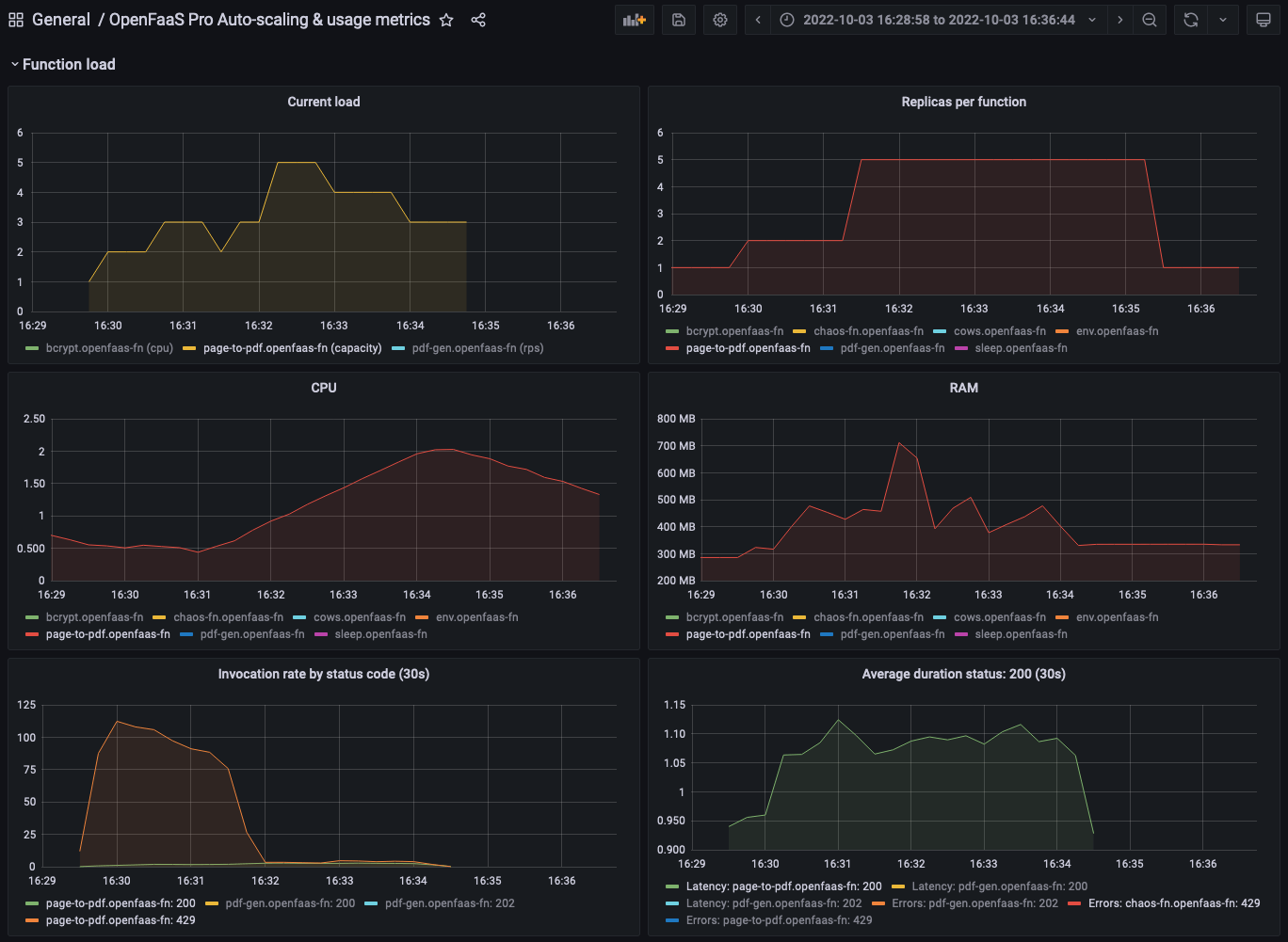
Function dashboard showing the replicas and invocation rate for the
page-to-pdffunction.
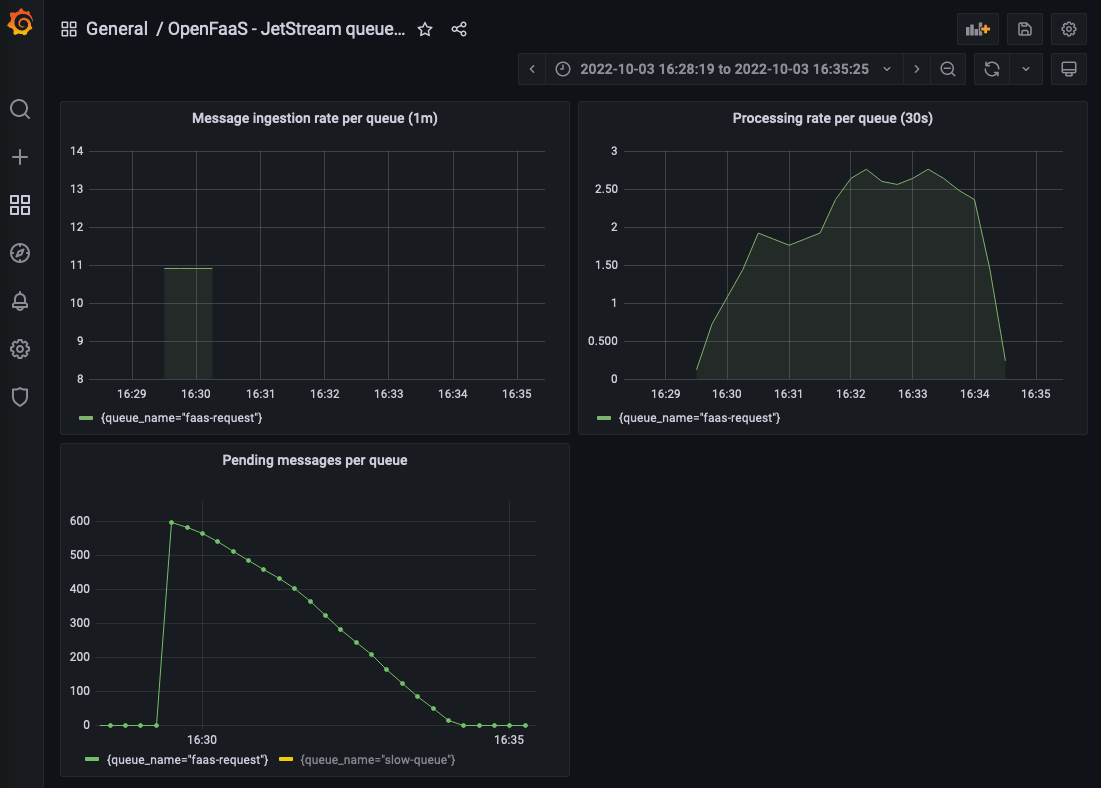
Queue-worker dashboard showing the number of pending message decline as the PDF are generated
Conclusion
A platform like AWS Lambda is purpose built for running functions at scale and can be very convenient if you have a lot of expertise with AWS already. One of the things we hear from customers is that they can find the timeouts and amount of retries possible restrictive. We also hear that the costs can be prohibitive for large-scale usage. One large company recently contacted us to tell us that had saved 60,000 USD per year, over the past 3 years by switching to OpenFaaS.
This blog post was written to show Kubernetes users that it is possible to autoscaling based upon requests, to limit concurrency in an intelligent way, and to scale out a task like PDF generation.
You may also like:
- How to process your data the resilient way with back pressure
- Web scraping that just works with OpenFaaS with Puppeteer
- Exploring the Fan out and Fan in pattern with OpenFaaS
To recap the post:
We created a workflow with two functions to generate PDFs from web pages using Puppeteer. Next we showed how this workflow can be configured to scale by making use of OpenFaaS Pro features like retries and autoscaling.
You can set a hard limit on the number of requests a function can handle at once. When the system is saturated we prevent dropping requests by buffering them and working through them gradually as capacity becomes available. Autoscaling can be configured to increase the capacity of the system so requests can be processed as quickly as possible.

Han Verstraete
Associate Software Developer, OpenFaaS Ltd

Alex Ellis
Founder of @openfaas.
